Копирование, перемещение и удаление блоков текста
Аналогично многим популярным текстовым процессорам и редакторам, Emacs позволяет вырезать, копировать и вставлять выделенные блоки текста. Корни этих операций для редактора Emacs уходят в бронзовый век компьютерной эры, поэтому описание команд могут показать современному пользователю несколько странными. Для избежания разночтений ниже приводится полезный словарик:
| region | Блок текста |
| point | Положение курсора |
| mark | Если перед курсором - начало выделяемого блока, Если после курсора - конец выделяемого блока |
| kill ring | Временная область памяти, куда помещается текст, который позднее будет скопирован или перемещен. В более поздних текстовых процессорах эту область часто называют "clipboard" или "буфером обмена". Хотя kill ring способен удерживать несколько блоков удаляемого или копируемого текста. |
| kill-region | Операция по удалению выделенного блока и сохранению его содержимого во временном буфере в kill ringВ современных текстовых процессорах эта операция известна как удаление блока в "буфер обмена". |
| copy-region | копирование выделенного блока в буфер обмена. |
| yank | Вставка блока, помещенного последним в буфер обмена, в текущую позицию курсора. Современные текстовые процессоры, использующие терминологию "clipboard" (буфер обмена), называют эту операцию "Вставка" ("Paste"). |
В современных версиях Emacs в меню Edit, оперирующему вышеописанными объектами и операциями, все чаще используется современная терминология.
Любая операция копирования, перемещения или удаления начинается с выделения блока текста. Для того, чтобы начать выделение блока, поместите курсор в начало блока и нажмите C-spase (или C-@, обе эти комбинации соответствуют команде set-mark-command), перемещая курсор стандартными клавишами, установите его в конце блока. Операцию выделения можно выполнять в обратном порядке: нажать C-spase в конце блока, а затем установить курсор в начало.
Некоторые версии Emacs отображают цветом выделяемую область. Однако многие версии этого не делают, поэтому так легко забыть какой именно текст выделяется. Это может привести к неприятностям при использовании впоследствии команды delete. Чтобы исключить подобные ситуации, существует команда exchange-point-and-mark (C-x C-x), которая позволяет проверить установленные границы выделенного блока путем "перепрыгивания" курсора в начало/конец блока. Повторное нажатие комбинации C-x C-x возвращает курсор в прежнюю позицию.
Чтобы выполнить операцию удаления блока delete (или "kill"), нажмите C-w или выберите команду Cut из меню Edit. Если блок был удален случайно, операция отката (yank) удалит этот блок из буфера обмена (kill ring) и вернет его обратно нажатием клавиши C-y. Если перед операцией отката курсор был перемещен, то блок текста будет возвращен в текущую позицию курсора.
Наличие в меню Edit пункта Select and Paste(в Xemacs отсутствует - прим. перев.) расширяет возможности использования команды yank. Select and Paste выводит на экран каскадное меню, содержащее несколько последних скопированных в буфер блоков.
Можно скопировать блок в "kill ring", выбрав команду Copy из меню Edit или нажав M-w (команда kill-ring-save). Данная процедура никак не скажется на редактируемом файле, но сделает доступным многократное использование однажды скопированного в буфер блока.
В текстовых процессорах, использующих буфер обмена (clipboard), удаленный или скопированный в буфер текст замещает уже находящийся там текст. В таких редакторах если планируется что-либо удалить или скопировать, чтобы позднее вставить фрагмент, то операцию по перемещению выделенного блока в буфер нужно выполнять непосредственно перед вставкой текста. Команда yank-pop редактора Emacs позволяет копировать блоки текста независимо от того, когда он был помещен в буфер. Количество удерживаемых в буфере обмена блоков зависит от версии Emacs.
Пример. В нижеприведенном тексте требуется переместить строку со словом "red", поставив ее после строки со словом "blue".
| yellow red black white blue green |
| yellow black white blue green |
| yellow black blue green |
| yellow black blue white green |
| yellow black blue red green |
Краткий справочник. Комбинации клавиш Emacs и PSGML
| C-f | forward-char | Перемещение на один символ вправо |
| C-b | backward-char | Перемещение на один символ влево |
| C-Left | backward-word | Перемещение на одно слово влево |
| M-b | previous-word | Перемещение на одно слово влево |
| C-Right | backward-word | Перемещение на одно слово вправо |
| M-f | next-word | Перемещение на одно слово вправо |
| C-v | scroll-up | Перемещение на одну страницу вперед |
| C-a | beginning-of-line | Перемещение в начало строки |
| C-e | end-of-line | Перемещение в конец строки |
| M-v | previous-page | Перемещение на одну страницу назад |
| M-b | previous-word | Перемещение на одно слово влево |
| M-f | next-word | Перемещение на одно слово вправо |
| C-p | previous-line | перемещение на одну строку вверх |
| C-n | next-line | перемещение на одну строку вниз |
| C-M-a | sgml-beginning-of-element | Перемещение на первый символ данных текущего элемента |
| C-M-e | sgml-end-of-element | Перемещение на последний символ данных текущего элемента |
| C-c C-d | sgml-next-data-field | Перемещение курсора в следующую позицию, где можно вводить данные |
| C-c C-n | sgml-up-element | Перемещение вверх по иерархии элементов в конец закрывающего тэга |
| C-M-u | sgml-backward-up-element | Перемещение вверх по иерархии элементов в начало открывающего тэга |
| C-M-d | sgml-backward-element | Перемещение в начало следующего вложенного элемента |
| C-M-f | sgml-forward-element | Перемещение в конец следующего вложенного элемента |
| C-d | delete-char | Удаление символа |
| C-@ | set-mark-command | Начало выделения |
| C-space | set-mark-command | Начало выделения |
| C-w | kill-region | Удаление выделенной области в буфер обмена |
| C-k | kill-line | Удаление фрагмента от курсора до конца строки |
| C-x C-x | exchange-point-and-mark | "Перепрыгивание" курсора в начало/конец выделенного блока |
| C-y | yank | Вставка удаленного текста в текущую позицию |
| M-d | kill word | Удаление слова |
| M-i | overwrite-mode | Переключатель Insert/Replace. Нестандартная команда Emacs, установленная строкой в файле ".emacs". |
| M-q | fill-paragraph | Выравнивание параграфа |
| M-w | kill-ring-save | Копировать в буфер обмена (kill ring) |
| M-y | yank-pop | Последовательная вставка в текущую позицию блоков, помещенных в буфер kill ring |
| M-C-\ | indent-region | Выравнивание строк выделенного фрагмента. В режиме PSGML - выравнивание тэгов, чтобы раскрыть структуру элемента. |
| C-q | quoted-insert | Вставка символьного эквивалента нажатой клавиши, даже если это командная комбинация |
| C-c C-e | sgml-insert-element | Ввод элемента через командную строку минибуфера |
| С-с < | sgml-insert-tag | Вставка открывающего тэга. Удобно использовать при добавлении тэгов к существующему тексту, поскольку содержание элемента можно редактировать |
| C-c / | sgml-insert-end-tag | Вставка закрывающего тэга. Удобно использовать при добавлении тэгов к существующему тексту |
| C-c C-r | sgml-tag-region | Вставка открывающего и закрывающего тэгов элемента для выделенного фрагмента текста |
| C-c - | sgml-untag-element | Удаление открывающего и закрывающего тэгов элемента. |
| C-c C-k | sgml-kill-markup | Удаление отмеченного курсором тэга |
| C-c Enter | sgml-split-element | Или, "вставить новый элемент, идентичный текущему". Разбить элемент вставкой закрывающего и открывающего тэгов |
| C-c o | sgml-comment | Макро-вставка в .emacs-файл. См. описание |
| C-M-k | sgml-kill-element | Удаление текста от текущей позиции курсора до конца следующего вложенного элемента |
| M-Tab | sgml-complete | Режим "дописывания" при вводе тэгов и других значимых слов |
| C-c C-q | sgml-fill-element | Выравнивание текущего элемента |
| C-c + | sgml-insert-attribute | Редактирование атрибутов текущего элемента с использованием подсказки |
| C-c C-a | sgml-edit-attributes | Редактирование атрибутов текущего элемента с использованием формы в отдельном окне Emacs |
| C-h | Меню справочных средств | |
| C-h ? | help-for-help | Описание использования встроенной подсказки |
| C-h a | command-apropos | Вывод на экран всех команд, где встречается указанное выражение |
| C-h k | describe key | Вывод описания комбинации клавиш, нажатой после C-h k |
| C-c C-c | sgml-show-context | Или, после C-c C-a, завершение редактирования атрибутов |
| C-x ' | next-error | Найти следующую ошибку в окне сообщений об ошибках |
| C-c C-o | sgml-next-trouble-spot | Переместить курсор к следующей потенциальной проблеме |
| C-c C-v | sgml-validate | Отправить документ на обработку |
| C-x 0 | delete-window | Закрыть текущее окно |
| C-x 1 | delete-other-windows | Закрыть все окна, кроме текущего |
| C-x 2 | split-window-vertically | Разделить окно по горизонтали |
| C-x o | other-window | Переход в другое окно |
| C-x b | switch-to-buffer | Отобразить другой буфер в текущем окне |
| C-x C-b | list-buffers | Отобразить список открытых буферов в новом окне |
| C-x C-s | save-buffer | Сохранить содержимое буфера в файле на диске |
| C-x C-w | write-file | Сохранить содержимое буфера в файле на диске под новым именем (если нужно) |
| C-x C-c | save-buffers-kill-emacs | Перед выходом из редактора запросить о необходимости сохранения измененных файлов |
| C-x C-f | find-file | Открывает и считывает файл в буфер |
| C-x i | insert-file | Вставка содержимое файла в буфер в текущую позицию |
| C-g | keyboard-quit | Прекращение текущей многошаговой операции |
| C-_ | undo | Откат последней команды |
| C-x ( | start-kbd-macro | Начать запись макрокоманды |
| C-x ) | end-kbd-macro | Закончить запись макрокоманды |
| C-x e | call-last-kbd-macro | Выполнить последнюю записаную макрокоманду |
| C-u (number) C-x f | set-fill-column | Устанавливает правую границу в столбце (number) |
| M-x | execute-extended-command | Отображение командной строки в окне минибуфера |
| C-s | isearch-forward | Прямой инкрементный (пошаговый) поиск |
| C-r | isearch-backward | Обратный инкрементный (пошаговый) поиск |
| M-% | query-replace | Предлагает ввести образец для поиска и текст для замены |
Сгенерировано TEItools
Крестоносцы
ОЛЕГ ТАТАРНИКОВ,
Опубликовано: 24.3.1997
© 2002, Издательский дом «КОМПЬЮТЕРРА» | http://www.computerra.ru/
Журнал «Компьютерра» | http://www.computerra.ru/
Этот материал Вы всегда сможете найти по его постоянному адресу: http://www.computerra.ru/offline/1997/189/431/
Введение
Ты так гонишься за тенью,
что теряешь наличие.
Из книги Иова
Концепции Интернета, первоначально разработанные в унитарной, централизованной армейской системе министерства обороны США, быстро вышли из "диктаторских пут" и воспринимаются сегодня как идеи всемирной общедоступной информационной магистрали. Любые попытки ограничения доступа, цензуры и внешнего воздействия на Сеть однозначно воспринимаются мировым сообществом в штыки. За широким внедрением Интернета в нашу жизнь не стоит никакая организация: это самоорганизующаяся система, и главный ее двигатель - все человечество. В этом основное отличие всемирной Сети от коммерческих сетей, в этом ее привлекательность для миллионов и ее сила. В таком свете неприглядно выглядят сторонники массовой "коизации" информационного обмена в России, стремящиеся загнать всех российских пользователей в прокрустово ложе единой кодировки. Тем более что носители этой идеологии составляют абсолютное меньшинство российских пользователей Интернета, пусть даже и самое активное. Причем благие намерения, которыми они при этом руководствуются, никак не служат оправданием для насильственного ограничения свобод и причинения дополнительных неудобств огромной армии пользователей, число которых продолжает стремительно расти. Ибо известно, куда таковыми намерениями обычно мостятся дороги.
Поводом для написания данной статьи послужили многочисленные послания, приходящие по электронной почте автору и многим другим "русскоязычным" абонентам Интернет-ресурсов в нечитабельном виде, то есть совершенно непригодные для чтения и никакой расшифровке не поддающиеся (проще говоря, безвозвратно загубленные - состоящие из одних "крестов"). Причем основными "виновниками" этого оказались провайдеры Интернет-ресурсов, как раз и обязанные оградить своих клиентов от подобных казусов.
Пытаясь разобраться во всех существующих проблемах и найти возможные пути решения, я обратился непосредственно к тем, кто максимально заинтересован в преодолении существующих трудностей, то есть к разработчикам программного обеспечения, Интернет-провайдерам и, естественно, их клиентам.
При всех очевидных разногласиях, существующих между этими группами (каждая из которых преследует несколько разные цели с одним общим знаменателем - избавить себя от необязательной работы), необходимость их сближения для понимания общих проблем очевидна.
Итак, существуют три основных Интернет-ресурса (проблема с русским языком для них одна, а решения могут быть и различные):
электронная почта (Mail); телеконференции (News); WWW-ресурсы.
В ближайшей перспективе, видимо, не удастся уйти от использования в Сети кодировки KOI8-R (сказывается инерция крупнейших Интернет-провайдеров). Остается лишь минимизировать ущерб от такой "сектантской" приверженности. Но даже при всеобщем стремлении к единству, будущее, по общему мнению, принадлежит набирающей силу универсальной кодировке Unicode, а в дальнейшем целесообразен перевод всех Интернет-ресурсов на HTML-формат (или какой-либо другой, который придет ему на смену) с передачей адресату текста вместе со всеми используемыми в нем шрифтами и версткой, что решит сразу несколько проблем, в том числе и с национальными алфавитами.
Электронная почта
Прибежали в избу дети, второпях зовут отца:
Тятя, тятя, наши сети притащили мертвеца.
А. С. Пушкин
Электронная почта - это частное дело двух человек (отправителя и получателя). В идеале производитель клиентской программы может обеспечить пользователя возможностью перевода из кодировки (одной из возможных, реально - это две-три), в которой сообщение поступило, в локальную, принятую на данной компьютерной платформе и/или операционной системе, и обратно (в соответствии, например, с именами в MIME charset). Но только возможностью! Чтобы пользователь всегда мог от нее отказаться и передавать сообщение как ему угодно. В любом случае этого не должен делать сервер. Вообще, какие-либо действия с корреспонденцией (за исключением пересылки) необходимо запретить категорически, ибо они напоминают перлюстрацию писем - не его (сервера) это собачье дело, он лишь почтальон, транспорт. Пока общие правила не выработаны, а программы работают "криво" - в ход идут всевозможные обходные маневры, который только усугубляют положение.
Единственный выход из этого - возложить всю ответственность на отправителя (по умолчанию). По отдельной договоренности можно, конечно, предоставить ему и другие возможности, но оставить право выбора. А что же мы видим сегодня? Владельцы серверов включают "неестественный интеллект" и насильственно перекодируют любое сообщение в KOI8-R. Помилуйте, господа! Откуда вы знаете, как и на каком языке я пишу послания в нашей многонациональной стране? Почему вы думаете, что я его не шифрую и не кодирую как мне заблагорассудится? Почему вы мните себя всемогущими и всеведущими и наделяете себя правом уничтожать частную информацию (а именно так зачастую и происходит). Посмотрите на кодовые таблицы. Что такое перекодировка? Это прибавление (или вычитание) к коду символа некоторого числа, определяющегося разницей между положениями символа в кодовых таблицах. Если в результате двойного или неправильного перекодирования полученный код "выскочит" из диапазона 0-255, то информация о символе будет утеряна! В качестве упражнения попробуйте перекодировать в KOI8-R, например, текст, представленный в альтернативной DOS-кодировке, принимая ее за Windows 1251, а потом попытайтесь что-либо восстановить…
Фанатики "запудрили мозги" даже фирме Netscape, и теперь браузером Netscape Navigator вообще невозможно пользоваться: он принудительно перекодирует, например, из Windows 1251 в KOI8-R, причем без возможности отключения и только в одну сторону - при отправке.
В конце концов, существуют Uuencode, MIME, Quoted-printable и прочие шифровальщики 8-битных символов, придуманные именно затем, чтобы обеспечить гарантированную передачу сообщений даже при "обрезании" 8-го бита (о чем будет сказано ниже), чтобы было удобно всем и каждый мог бы использовать "родную" кодировку, - а у нас пытаются всех загнать в одно стойло. Конечно, далеко не все почтовые программы могут автоматически корректно восстановить текст из бессодержательного набора букв, цифр и знаков препинания, в которые он после этого превращается. А что делать? Если вы не намерены производить массовые рассылки неизвестным абонентам, то со своими адресатами всегда можете договориться. Причем в этом случае неплохо воспользоваться и каким-либо специальным шифром (а такую возможность начисто отвергают сторонники серверной перекодировки).
Да, посылая письма неизвестному адресату (с которым вы не успели договориться о приемлемом для вас обоих формате), вы рискуете попасть впросак. Но это должно быть на вашей совести! Здесь проще прибегнуть ко всем кодировкам одновременно или написать по-английски. Или по-русски, но английскими буквами (что многие и делают, даже вопреки потугам "слишком умных" провайдеров). Нынешнее положение вещей недопустимо! Программы от версии к версии изменяют правила оформления, форматы данных и кодирование. Серверы обретают "неестественный" интеллект и "непроходимую" настойчивость, а пользователи, вместо того чтобы заниматься делом, - ищут средства для "обмана". И существующая ситуация настолько зыбкая, что гарантий не может дать никто, а благодаря всевозможным ухищрениям, положение только ухудшается. Посудите сами, если вам прислали письмо в какой-то конкретной кодировке (из двух-трех возможных реально), пусть даже неудобной для вас, - его можно перекодировать и самостоятельно. Если же по пути оно прошло через две-три "насильственные" трансформации, то информация безнадежно утеряна.
Конференции по интересам
>>>> А вот зайца кому?
>>> Мне!
>> Й чОЕ!!
> i mne!!!
and me too!!!!
Телеконференции - это единственное место, где вопрос, какую кодировку применять, перестает быть личным делом каждого. Если вы отправляете сообщение для публичного прочтения, то, очевидно, его необходимо унифицировать.
Конечно, поддерживать несколько различных кодировок для конференции довольно глупо, разумно остановится на одной. Исторически - это KOI8-R, пусть она и остается до лучших времен. В конце концов, участие или неучастие в обсуждениях - это также личное дело каждого и его собственная проблема. Хочешь участвовать в существующих телеконференциях - "коифицируйся", не хочешь - создавай свои (на своем сервере и в "своей" кодировке). Есть участники - есть конференции, уйдут участники - пропадут и конференции.
По моему личному мнению, информационная ценность публичных телеконференций довольно низкая, серьезные обсуждения уходят в специализированные списки рассылки, избегая информационного "засорения", оперативную информацию всегда можно почерпнуть в on-line, а поболтать - на chat. "Агрессивные" фидошники, отстаивая свою сеть как альтернативу Интернету, ожидают, порой, ответа на свои послания месяцами, а несовпадение пришедших вопросов и ответов на них, рождает дополнительную путаницу.
Группа участников телеконференций не самая многочисленная в Сети, однако, как показывает опыт, самая влиятельная и… консервативная: "Ну КОИ8 все же было принято использовать. News, скажем, в ней приходится читать. До сих пор. А раз мне что-то приходится читать в КОИ8, все остальные кодировки меня раздражают" (Михаил Исаев, из обсуждения русской кодировки в телеконференции relcom.talk).
Однако и здесь больше вопросов, чем ответов. Больная проблема поддержки русского языка время от времени всплывает и в существующих конференциях, заставляя страсти разгораться с новой силой. Участвуя в этих обсуждениях, не стоит полагаться на мнения отдельных участников: некоторые из них, несмотря на юный возраст, - "махровые" консерваторы, о других складывается впечатление как о не обременяющих себя какой-либо полезной деятельностью болтунах, а всех их, похоже, объединяет чувство принадлежности к некому клану, основным атрибутом которого является приверженность к использованию кодировки KOI8-R. Может, она и необходима-то лишь для этого? Как хорошо почувствовать себя "крутым", установив на своей машине поддержку KOI8-R, и смотреть свысока на тех, кто этого еще не сделал, обзывая их при этом лохами или, по крайней мере, ламерами.
Но все же я выяснил точки зрения достаточно серьезных и известных в этой области людей: Андрея Чернова, разработчика почтовой программы UUPC/@ и инициатора предложения RFC 1489 (Internet Request For Comments), регистрирующего употребление русской кодировки KOI8-R в качестве рекомендательной для любого представления информации в сети, содержащего кириллицу (причем, как следует из заявки, - кириллицу вообще, без учета мнения других кириллических народностей), координатора релкомовских конференций Дмитрия Мартынова, а также других известных мне людей, причастных к становлению и развитию Интернет-технологий в России. Их мнения не во всем совпадают, и, уж конечно, не все они являются сторонниками "драконовских" мер.
Выступления в конференциях никого ни к чему не обязывают, поэтому приходилось проверять и перепроверять информацию, причем, как правило, тут же, не выходя из Интернета. В общем, основная часть сведений почерпнута в результате виртуального обмена. Причем несомненным достоинством последнего является возможность его принудительного отключения в любую минуту. Так как конференции являются публичными и общедоступными, я оставляю за собой право свободно цитировать некоторые мнения, а соображения, высказанные в личной переписке, - с согласия авторов.
Итак, ключевое мнение: "Не было бы стерверов в 1251 - поставили бы виндовозники на своих машинах KOI8-R, никуда бы не делись"(Дмитрий Мартынов). А тем временем Windows-"стерверов" становиться все больше и больше…
Русская кодировка
Для настоящего понимания духа предмета
особенно важно овладеть определениями.
С. К. Клини, Математическая логика
Что такое кодировка? Это метод компьютерного представления множества различных символов, включающего буквы алфавита, знаки пунктуации, цифры и специальные знаки.
Обсуждая обременительное сосуществование нескольких различных кодировок для представления русских букв и связанные с ним проблемы, озираются чуть ли не на Кирилла и Мефодия. Выпендрились, понимаешь... Забывая, что даже американцы, по общему мнению, "затачивающие" все под себя, до недавнего времени имели по крайней мере две кодировки: EBCDIC (Extended Binary Coded Decimal Interchange Code) и ASCII (American Standard Code for Information Interchange).
EBCDIC-схема издавна применялась фирмой IBM в мэйнфреймах и использовала 8 бит для представления символов. Но американцы решили сэкономить (американский набор символов самый маленький, даже англичанам требуются дополнительный значки, например, для обозначения фунтов стерлингов) и приняли схему ASCII, где для кодирования символов используется только 7 бит из байта. Американцы решили, что для представления печатных символов с лихвой хватит 128 позиций (в самом деле: 27 строчных букв, 27 прописных, 10 цифр, десяток знаков препинания и все), да еще и запас останется.
Были и другие кодировки, и долгое время все они сосуществовали на равных. Но вдруг правительству США "взбрело в голову" поддержать ASCII-кодировку на государственном уровне, и все подравнялись на главного заказчика. А централизованное и плановое советское народное хозяйство даже такой малости не сделало, а наоборот, видимо, в издевательских целях, приняло несколько ГОСТов по кодировкам, а затем и вообще пустило это дело на самотек. Скоро все "мертворожденные" ГОСТы были забыты, и мы сегодня пользуемся тем, что нам "подарили" американские "русификаторы" (национальная принадлежность конкретных русификаторов в данном случае значения не имеет, так как все "живущие" локализации делались с подачи западных фирм или по их "вине").
Таблицы символов Extended ASCII (ISO8859-5, DOS 866, WINDOWS 1251, Macintosh)
Без конца сбиваясь, при луне
Трое лбов считали ребра мне.
Сбились в третий...
Сбились в пятый раз...
Как все плохо делают у нас!!!
С. Статин
Расширение таблицы ASCII произошло по требованию европейских стран (причем, опять же, вплоть до правительственного вмешательства). Для представления печатных символов большинства европейских алфавитов пришлось "вернуть" только восьмой бит в байте. Лишний бит - это еще 128 символов, и там смогли разместиться все диакритические знаки национальных алфавитов. Так была создана таблица символов Extended ASCII. Однако уже созданное к тому времени американское программное обеспечение было рассчитано на 7-битную кодировку, и возникло множество проблем, описание которых выходит за рамки данной статьи.
Наш алфавит отличается от латинского полностью, и символов в нем больше (66), поэтому он, как и некоторые другие европейские алфавиты, не уместился в таблицу Еxtended ASCII (ISO 8859-1, или Latin-1, ISO - International Standards Organization, то есть Международная организация по стандартизации). Пришлось придумывать отдельные таблицы на каждый язык, и наша получилась пятой по счету - ISO 8859-5.

Полученный в результате чистый продукт так и не прижился. ISO 8859-5 подкосила и российская компьютерная раздробленность, и разработка IBM - PC, в операционной системе которого Билл Гейтс и Microsoft применили псевдографику (вертикальные и горизонтальные черточки, различные уголки, прямоугольники и т. д.), занявшую места русских букв в таблице ISO 8859-5. Пришлось срочно "распихивать" русские буквы по местам, не занятым псевдографикой. Забавно, что стандартов никто не принимал (точнее, их было несколько, поэтому никто не обращал на них внимание), но проблема утряслась, и в результате русификации MS-DOS появилась "альтернативная" кодировка 866.
Почему вышеупомянутой фирме Microsoft не подошла 866-я для Windows, понятно - отпала необходимость в псевдографике. А вот ISO 8859-5 не подошла, похоже, из принципа делать все самостоятельно (хотя А. Чернов утверждает, что и CP1251, и CP878 (KOI8-R) основываются на стандартах фирмы IBM - и Microsoft тут совершенно ни при чем, CP - Code Page, то есть кодовая страница). Так или иначе, но для "русских" Windows была принята кодировка Windows-1251 (CP1251), самая распространенная сегодня.

Не забыть бы также и пользователей компьютеров Macintosh, которым вообще никто не указ! Для них сделали специальную кодировку, просто так, для праздника, чтобы им жизнь медом не казалась и они бы использовали только "родной" софт.

А ISO 8859-5, чтобы не обиделась, стали величать основной, но ею все равно почти никто не пользуется.
Теперь представим себе российского программиста, создающего информационную систему для своего предприятия. Ему нужна соответствующая кодовая таблица и программа, которая ее поддерживает. Если программа "сильно" американская (не обрабатывает восьмой бит), то он ее модифицирует или пишет свою. В конце концов проблема решается.
Сложнее обстоит дело с коммуникационными программами. Электронная корреспонденция ходит разными, подчас непредсказуемыми путями. И "злобная" американская машина может "обрезать" (обнулить) 8-й бит. Сейчас таких машин практически не осталось (хотя мне сразу же указали на такого "монстра", как CompuServe), во всяком случае, они не являются промежуточными при пересылке.
Однако когда Интернет в России только появился (90-91-й годы), эта возможность была далеко не гипотетическая, а очень даже реальная. Так что следующая кодировка - KOI8-R, использовавшаяся в середине 80-х, когда были еще живы 7-битные терминалы, достаточно хорошо проявила себя и в новом, сетевом применении. Сложилась определенная, довольно консервативная российская сетевая культура, представители которой занимают пока ключевые посты, так что даже массовый наплыв пользователей Microsoft Windows (более 90 процентов клиентов) пока не может ее снести. Кто победит, и победит ли кто вообще - посмотрим. Думаю, что проблема отомрет сама собой (причем, может быть, и вместе со структурой в ее нынешнем виде), и для этого есть все основания. А пока процветает "насильственная коизация".
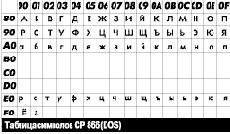
Таблица символов KOI8-R
Представьте себе письмо, написанное по-русски, отправленное электронной почтой и нарвавшееся по пути на "злобный" американский сервер (а у нас, порой, между соседними домами письма через Америку ходят - провайдеры никак не договорятся), срезающий у всех писем восьмой бит. После такого "обрезания" те буквы, которые были русскими, становятся латинскими. Теми, чей номер в таблице меньше ровно на 128. Значительное число букв нашего алфавита имеет фонетические аналоги в латинском. Например, П и P, Р и R. К тому же есть несколько совпадающих и по написанию. Значит, целесообразно расположить русские буквы таким образом, чтобы они отличались от похожих латинских на 128! Тогда потеря восьмого бита превратит сообщение в некую транслитерацию (состоящую из одной латиницы), смысл которой все-таки можно восстановить и прочитать по-русски. Неприятно, но понятно.
KOI8-R (код обмена информацией, 8 бит) - это и есть такая таблица. И именно она с самого начала применяется для обмена почтой и новостями в России. Первые письма так и ходили на языке "ruglish", том самом фонетическом эквиваленте, когда "здравствуй" выглядит как "zdrawstwuj". Однако все письма читались! А что делать - mnogie do sih por tak pishut. Но сегодня это уже по другим причинам.

Итак, KOI8-R сегодня - сетевая кодировка de facto. Почему? Вышеописанными соображениями уже можно было бы пренебречь. Сегодня некоторые приверженцы ссылаются на описание кодировки в RFC 1489 (Internet Request For Comments), предложенное в июле 1993 года Андреем Черновым, а значит, и "стандартность". Ну и что? В других RFC предлагается и ISO 8859-5 (например, в RFC 1700). Да и вообще, RFC - это рекомендации, как и все в Интернете. А если рекомендации не согласуются с жизнью и причиняют неудобства абсолютному большинству пользователей, то не следует ли принять другие, более удобные рекомендации?
С точки зрения большинства пользователей, безусловный лидер - Windows 1251. Единственный "серьезный" аргумент против нее (за исключением традиции) высказал Д. Мартынов: с позиции программиста 1251-я плоха, потому что буква "я" попадает на место 0xFF, из-за чего некоторые программы на Си, считающие (char)(getchar())==-1 признаком ошибки, ведут себя с этой буквой неадекватно. Но тогда нехороша и KOI8-R, у которой там же "Ъ", и годится только "мертвая" ISO 8859-5.
Кроме того, "безнадзорная" кодировка KOI8-R существует в таких безобразных реализациях, что серьезно встает вопрос о профессионализме при ее использовании. То есть там буква "Е", то нет, то есть псевдографика, то нет. Все существующие шрифты в этой кодировке "кривые" (абы только писалось), и работать с ними неприятно. Предвижу возражения о несостоятельности таких обвинений, но ведь факт пренебрежительного отношения к шрифтам в KOI8-R о чем-то говорит (я нарочно проверил добрый десяток). Не предусмотрены и специальные русские эпистолярные символы: длинное тире и кавычки елочкой. "Разработчики" этих шрифтов явно не подозревали, что минус, знак переноса и тире - разные символы. Так что вряд ли и эта кодировка станет единственной сетевой в России. И задержать ее может только консерватизм сегодняшних серверов-"крестоносцев" (на них все настроено именно под нее) и несовершенство программного обеспечения.
То, что провайдеры утверждают о невозможности что-либо изменить, - враки! В свое время возникла гораздо более серьезная, причем всемирная проблема с IP-адресами (стало не хватать адресов при кодировании принятым тогда способом), а на них вообще все держится. Однако же под давлением общественности пришлось осуществить необходимые реформы. А можно было бы также сказать: "у нас все и так хорошо работает, просто будем давать новые адреса по мере выбытия владельцев старых, а остальные потерпят". Просто, удобно, и не надо ждать, пока все перестроятся.
Появление новых, более демократичных провайдеров и продолжающаяся экспансия Windows-клиентов и серверов может резко изменить положение, превратив вчерашних "диктаторов" в тихую секту, типа "адвентистов седьмого дня".
А существует ли вообще кандидат на единую кодировку? Да, и похоже, его вступления в права осталось ждать недолго, хотя и совсем по другим причинам…
| Платформа | Число посещений | Удельный вес, % |
| Windows | 19959 | 52,3 |
| Macintosh | 9460 | 24,7 |
| OS/2 | 3567 | 9,34 |
| Unknown | 2004 | 5,25 |
| Unix | 1708 | 4,47 |
| Amiga | 1265 | 3,31 |
| Sega Saturn | 131 | 0,34 |
| WebTV | 52 | 0,13 |
| NeXT | 10 | 0,02 |
| VM/CMS | 6 | 0,01 |
Сайт www.medlux.ru показателен еще и тем, что отношения к компьютерной тематике не имеет (наличие лекарств в аптеках Москвы и другая медицинская информация), а обращения к нему происходят в основном из стран СНГ.
(Информацию предоставил Web-мастер Александр Зотов.)
| Количество посещений | Платформа |
| 39030 | Win95 |
| 27094 | Windows неопозн. |
| 10321 | Win16 |
| 2903 | WinNT |
| 1440 | Win32 |
| 1254 | FreeBSD |
| 1181 | SunOS |
| 863 | Unix unknown |
| 595 | Macintosh |
| 583 | OS/2 |
| 540 | Linux |
| 192 | Mac_PowerPC |
| 156 | HP-UX |
| 132 | AIX |
| 97 | BSD/386 |
| 80 | OSF1 |
| 34 | AlphaServer |
| 28 | BSD/OS |
| 16 | OpenVMS |
| 14 | IRIX64 |
| 7 | Alpha |
| 6 | WebTV |
MS - 93,3%, Unix - 5,1%, Mac - 0,9%, OS/2 - 0,7%.
Нас спасет Unicode
Откуда у меня такой оптимизм относительно использования Unicode? Этот стандарт разрабатывается консорциумом Unicode, куда входят представители таких фирм, как Taligent, Microsoft, Xerox, NeXT Computer, Sybase, и других. Появился он в операционных системах Unix, NeXT, Windows NT, а затем и в Windows 95 и служит для универсального представления символов. Ему не нужны отдельные таблицы, как в ISO 8859-1,2,3,4,5… Символы представляются шестнадцатью битами (двумя байтами), и каждый символ фактически содержит код языка, к которому он принадлежит, что дает возможность выбора языковых и шрифтовых средств исключительно на основе кода символа, а не с помощью дополнительных указаний на кодовую таблицу типа charset: koi8-r. Таким образом, даже если заголовок письма неверен, испорчен или вообще отсутствует, содержание все равно восстанавливается. Другая возможность, решающая в пользу применения Unicode - употребление смешанных языков в корреспонденции, что особенно актуально для нашей многонациональной страны (в конце концов, в Unicode можно включить и все используемые сегодня кодировки). По утерянной традиции русского дворянства все письма положено писать на смеси "французского с нижегородским", а продвинутые смогут цитировать и Лао Цзе в подлиннике. В Unicode можно включить и специальные типографские и оформительские символы, принятые для разных стран. В общем, отличный кандидат на универсальную кодировку (если угодно, с последующим перекодированием у "несознательных" клиентов, ведь никто не собирается отменять "исторические" традиции, сложившиеся в различных операционных системах, а Unicode сам сохранит такое соответствие). Кроме того, поддержку Unicode обеспечивает и Java - модный сегодня язык программирования для Интернета и сетевых приложений.
Общее число иероглифов (включая те, что используются в одном- единственном древнем манускрипте) превышает 50 тысяч. Причем японская/китайская иероглифическая письменность устроена так, что сочинить новый иероглиф может, в принципе, любой. Тут уж и 32 разрядов не хватит. На практике, правда, изобретение иероглифа считается высшим пилотажем и попускается только великим, а не всякому с улицы. Однако в 50-х годах японцам все это самим надоело, и они оставили только 1850 иероглифов плюс некоторые наиболее излюбленные прочие, а остальные велели писать алфавитом. Но, как всегда, нашлась куча несогласных, которые явочным порядком продолжают использовать "отмененные" иероглифы. Тем не менее эти 1850 с плюсом в Unicode вполне умещаются. В Китае несколько сложнее, но и там предприняты шаги для упрощения письменности.
|
Компьютер понимает по-китайски ("Popular Science" #8, 1996. Перевод "Наука и жизнь" #1, 1997.) Большие проблемы для широкой компьютеризации Китая создает иероглифический китайский шрифт. Если для большинства других языков хватает стандартной клавиатуры со 102 клавишами, то при 13 тысячах иероглифов клавиатура заняла бы большой стол. И даже упрощенный вариант письменности "всего" с 5 тысячами знаков не позволяет представить себе портативный китайский персональный компьютер. Сейчас большинство китайских пользователей работает на английском языке, а если приходится все же печатать китайские тексты, то пишут их произношение латинскими буквами (кстати, в 50-х годах пытались ввести такую систему письма, но позже отказ от иероглифов был сочтен непатриотичным). Некоторые фирмы выпускают специальные клавиатуры для китайского языка. На клавишах нанесены отдельные элементы иероглифов. Чтобы скомпоновать целый иероглиф, приходится использовать до шести клавиш. Поэтому сейчас разрабатываются программы распознавания китайской речи, устной и письменной, чтобы компьютеру можно было диктовать или писать специальным электронным пером прямо на экране. Американская фирма "Моторола" предложила недавно программу распознавания китайского письма, делающую при работе всего 5 процентов ошибок даже при использовании всех 10 тысяч иероглифов. Надо сказать, дело облегчается тем, что практически у всех китайцев хороший и почти одинаковый почерк. Фирма "Эппл" разработала программу для печати под диктовку на основном (пекинском) диалекте. Не оставлены и попытки ввода китайских текстов с клавиатуры. Одна канадская фирма создала 10-клавишную клавиатуру с наиболее распространенными элементами иероглифов. Компьютер работает со специально разработанной подсказывающей программой. При нажатии одной-двух клавиш на экран выводится ряд иероглифов, имеющих в себе эти элементы, и оператору остается только выбрать нужный. В среднем на создание одного иероглифа при такой системе уходит 2,7 удара по клавишам. В самом Китае фирмой "Сяочжун Компьютер" предложена клавиатура из 24 клавиш, основанная не на внешнем виде, а на произношении иероглифов. |
И не только для белых
Сидит собака и стучит лапами по клавиатуре.
- Собака, ты что делаешь?
- Почту пишу.
- А как же они с тобой переписываются?
- А я им не говорю, что я собака.
Раньше, для того чтобы любой пользователь мог войти в Интернет, ему необходимо было кое-что знать о своем компьютере и грамотно настроить специальную программу (а то и не одну). В общем, каждый счастливый обладатель сетевого доступа чувствовал себя неким гуру. В последнее время, особенно с появлением таких операционных систем, как Windows 95, большинство ожидает от машины, что она сама себя настроит, наладит, договорится с другими машинами, а пользователю останется только получать удовольствие. И это недалеко от истины. Конечно, необходимо признать и существование того, что старожилы называют ламерством, то есть навязчивое желание малообразованных неофитов навязать свою точку зрения на проблему, с которой тот недавно познакомился "на лету". Но таковы реалии сегодняшнего дня, ничего с этим не поделаешь, остается только смириться, предоставив полную свободу пользователю в рамках некой осознанной необходимости. В конце концов процесс так или иначе нормализуется, и все встанет на круги своя. Все необходимые средства сегодня интегрированы в операционные системы, остается лишь прочитать пару страниц руководства, и если бы не русский язык, то думать вообще бы не пришлось. Но, к сожалению, обладание "великим и могучим" не дает закостенеть мозгам и отвлекает людей от их непосредственной деятельности.
Итак, мы имеем несколько кодировок для представления кириллицы. Все они объективно существуют, все используются. Провайдеры желают иметь в Интернете одну русскую сетевую кодировку. Так как и почта, и новости исторически ходили в KOI8-R, им ничего не хочется менять и они готовы распространить это и на другие ресурсы (в том числе и на WWW). Пользователи не желают ничего "подкручивать" и налаживать в своих программах для того, чтобы обмениваться информацией по-русски. По большому счету, правы последние. Слишком дорогую цену им порой приходится платить, перенастраивая программы, работающие с Сетью (а их становится все больше и больше). К тому же клиенты справедливо считают это работой тех, кто им доступ в эту Сеть и предоставляет. Конечно, со временем все установится, каждый найдет своего провайдера, ибо спрос, как известно, рождает и предложение, а клиент всегда прав!
Для тех, кто не хочет ничего налаживать, существуют готовые решения, многие провайдеры предоставляют собственные программы (правда, далеко не всегда лучшие). Например, для DOS есть пакет под названием UUPC (в DOS'овской модификации А. Чернова - UUPC/@). Вы можете его установить, пользоваться только им, только под DOS и "поминать" время от времени господина Чернова. Зато он будет конвертировать отправляемую корреспонденцию в кодировку KOI8-R, приходящую - в альтернативную, соблюдать международные стандарты и думать о российской доле. Вам об этом думать не надо. Строго говоря, протокол UUCP, которым пользуется программа UUPC, не относится к Интернет-протоколам и безнадежно устарел. Для того, чтобы почта дошла до адресата, ее необходимо преобразовать в Интернет-формат, что происходит на сервере провайдера (если, конечно, он поддерживает UUCP).
Основные аргументы в пользу UUPC - его неприхотливость к ресурсам, способность работать на "слабых" компьютерах под DOS, благосклонное отношение к частому пропаданию модемного соединения и простота установки/настройки. Для тех, кто хочет или может себе позволить только электронную почту, UUPC - идеальное решение, аналогов которому нет и скорее всего уже никогда не будет.
Если хочется чего-нибудь покрасивее - поставьте Windows и возьмите Microsoft Internet Mail & News. Они довольно аккуратно сделаны, желающие могут выбрать KOI8-R, и программы сами все перекодируют туда/обратно в CP1251 и проставят правильный charset (а без указания - не перекодируют). Пожалуй, это единственный иностранный продукт, способный корректно работать со всеми российскими "заморочками" и ориентированный на будущее. Поддерживается MIME-стандарт (Multipurpose Internet Mail Extensions), в том числе восьмибитная кодировка, а также кодировки Base64 и Quoted printable. Принятые звуковые и видеофрагменты пакет правильно экспортирует в соответствующие приложения.
Поскольку Internet Explorer, в состав которого входит Internet Mail, является браузером, то он может отправлять послания и в HTML-формате. Господин Чернов, по его утверждению, "заставил" Microsoft приобщиться и к KOI8-R, причем корректно "подкрутить" и ввод форм, и имена кнопочек в Explorer, и при этом ему не удалось его "сломать", как в случае с Netscape, так что для Windows 95 скоро не будет никаких проблем, если конечно сами провайдеры, по доброте душевной, не постараются.
Возможность работы с отложенной доставкой реализована великолепно. Кроме того, Internet Mail позволяет управлять модемным соединением: самостоятельно устанавливает связь, отправляет и получает почту. По окончании приема/передачи модем автоматически отключается. Можно даже составить расписание автоматических сеансов связи.
О программах Microsoft Mail & News я в последнее время слышал только хорошее (дырки латаются очень быстро!), хотя сам ими не пользуюсь. Даже недостаток - не показывают картинок в тексте письма (как это делает Netscape), интерпретируется многими как достоинство (не будете без конца порнографию смотреть). Может быть, слишком простая книжка адресов (невозможно организовать иерархию), и все... Зато нет проблем с русскими буквами! Хочешь так, хочешь этак. Простые, приятные и красивые программы (новый Netscape Communicator 4.0, похоже, смотрел уже на Microsoft, но кроме интерфейса ничего не высмотрел и по-прежнему для российского употребления практически не пригоден).
Таким образом, несмотря на то, что я с момента выпуска и по сей день работаю с программами Netscape, рекомендую пользователям Windows 95 именно Microsoft Mail & News. Да и Internet Explorer становится гораздо лучше. И к тому же работает...
Для любителей трудностей
Всякое изменение тела, будь то болезнь или здоровье, сводится к перемещению веществ в пространстве… но демоны не могут произвести этого движения, так как это доступно только богу. Отсюда ясно, что демоны не могут произвести никакого, по крайней мере фактического телесного изменения и что в силу этого подобные превращения должны быть приписаны какой-либо тайной причине.
"Молот ведьм"
Существует несколько способов обработки передаваемой электронной почты (аналогичные рассуждения применимы и к новостям), а соответственно, и возможностей безнадежно испортить сообщение. Эти способы естественным образом вытекают из того, как организована передача почты. Пользователь взаимодействует с почтовой программой, которая позволяет ему отправлять и принимать письма, организовывать хранение, вести адресные книги и т. д. Можно сказать, что основная функция почтовой программы - предоставить удобный пользовательский интерфейс. Чтобы отправить или получить письмо, почтовая программа обращается к почтовому серверу, который не имеет пользовательского интерфейса, зато владеет тонкостями маршрутизации корреспонденции. Затем напрямую или через промежуточные машины письмо передается другому почтовому серверу, который обслуживает адресата. Тот кладет письмо в персональный почтовый ящик, откуда его забирает почтовая программа получателя.
Предположим, что письма надо перекодировать. По "сложившийся традиции" это может сделать и почтовая программа, и сервер. Первому варианту я уже выказал предпочтение, и с учетом существующей практики ущерб от такого решения минимален.
Перекодировка доставщиком
Съесть не съем, но надкушу каждое…
У провайдеров Интернет-услуг за годы работы "сложилось мнение", что будет гораздо лучше, если программное обеспечение почтовой машины само будет перекодировать почту. Тогда единственное, что нужно сделать пользователю, - отключить шифрование восьмибитных символов (иначе, по понятной причине, никто не сможет потом что-либо восстановить). Подчеркну еще раз, что я активный противник такого подхода и даже многие провайдеры считают его временной мерой.
Отправлением/доставкой почты на сервере занимаются две программы. Первая служит для отправки почты и называется "SMTP-сервер". SMTP (Simple Mail Transfer Protocol) - это протокол передачи писем в Интернете. Служба SMTP и принимает письма, складируя их на почтовой машине. Непосредственно пользователю, по его инициативе, письма передает другая программа - "POP3-сервер" (Post Office Protocol).
Дальше все очевидно: сервер SMTP "заставляют" переводить письма из кодировки отправителя в сетевую кодировку (сегодня это KOI8-R). Сервер же POP3 должен переводить письма из KOI8-R в ту кодировку, которую хочет принимать получатель. В какую только?.. И из какой?..
Откуда и куда конвертировать
Откуда берут информацию о кодировке письма:
из служебных полей заголовка письма из конфигурационных файлов; имеют выделенный виртуальный сервер для работы с каждой из кодировок; определяют кодировку по содержимому письма.
Первый подход перекладывает ответственность на почтовую программу пользователя. Она должна включить в заголовок письма правильный charset. Это был бы самый правильный подход для какой-нибудь Германии, но только не для России. У нас даже координаторы конференций используют неправильный charset, а потом обвиняют слишком умный софт, который все делает через задницу (читай - соблюдает стандарты), когда у всех остальных (читай - не соблюдающих никаких соглашений, а просто "делающих как я") - все нормально. При всеобщей безответственности и поголовном "обмане" программ и стандартов такое решение приводит к печальным последствиям.
Второй подход примитивен. Администратор почтовой машины раз и навсегда определяет, что клиентская машина с таким-то сетевым именем или адресом работает в кодировке, скажем, Windows 1251. И теперь вся корреспонденция, отправляемая с данной машины, считается представленной только в этой кодировке. А если у машины нет постоянного адреса, как обычно и бывает, а пользователь, соединяясь с провайдером, получает на время каждого сеанса динамический IP-адрес, но все равно обращается к своему почтовому серверу и почтовому ящику, то такое решение не работает. Я уж и не говорю о том, что с этой машины нельзя будет отправлять ничего другого.
Выделенный виртуальный сервер. Давайте запустим на одной почтовой машине три-четыре почтовых сервера одновременно, по одному на каждую кодировку, и каждому серверу присвоим отдельное имя, например: win.mail.access.ru, alt.mail.access.ru, koi.mail.access.ru, iso.mail.access.ru. Предложим пользователям Windows обращаться за своей почтой на сервер win.mail.access.ru, пользователям DOS - на alt.mail.access.ru и т. д. Клиенту достаточно при конфигурации своей почтовой программы правильно указать адрес почтовой машины. Причем в этом случае, разделив уходящий SMTP-поток и приходящий POP3 на разные кодировки, можно получить дополнительную гибкость. Предположим, что Netscape, как было сказано выше, принудительно переводит Windows 1251 в KOI8-R, а обратного процесса не производит. Тогда мы определяем в нем SMTP - KOI, а POP3 - Win, и, таким образом, исходящую корреспонденцию перекодирует Netscape, а входящую - сервер. Можно попробовать и другие цепочки с экзотическими адресатами - вариантов много. Это, на мой взгляд, самое правильное решение (если вообще что-то надо делать). Пользователь все равно должен проставить имя сервера, и не надо считать его таким глупым и не оставлять никакой свободы, как в предыдущем случае. И всегда можно зарезервировать вариант по умолчанию, который ничего не делает, а просто передает, как ему и положено. У меня именно такой провайдер. И я его хвалю не потому, что он мой, - а он мой, потому что так делает.
Идея автоматического определения кодировки при всей кажущейся заманчивости мне совсем не понравилась. Надежно определить, в какой кодировке представлен текст, да еще с нашей грамотностью, по технологии распознавания сомнительно. Конечно, такой программе достаточно лишь научиться отличать русский язык от абракадабры. А если мне вздумается писать по-татарски! Причем некоторые провайдеры высказывают мнение, что нераспознанные письма не следует отправлять адресату! Ну и как их назвать после этого? Отправлять по почте любую абракадабру - конституционное право пользователей.
Универсального решения сегодня в любом случае не существует. Даже тогда, когда пытаешься предусмотреть все. Из приведенного в конференции примера Григория Наумовца: "Недавно мне было нужно разослать одно сообщение на кириллице через mailing list нескольким десяткам людей с разными серверами (одни перекодируют КОИ8<->1251, другие нет) и мэйлерами (от Eudor'ы до Bmail'а). Думаю, надо сделать так, чтобы кириллица у всех была сразу же видна без переключения фонтов или кодировок. Поэтому включаю в письмо четыре куска: (1) English, (2) КОИ8, (3) 1251 и (4) такой, который должен превратиться в КОИ8 в случае перекодировки POP-сервером или софтом получателя по таблице КОИ8->1251. Ну и? Все равно от одного из Dmail-овских адресатов пришел ответ: "не могу прочесть письмо, так как в нем нет строки begin" (???). Оказывается, один серверок по дороге оказался еще умнее меня и зачем-то закатал мое письмо в Base64".
World Wide Web
" Всемирная паутина" живет по своим законам. Вопросы верстки в HTML уже давно раздражают профессионалов, для них это два шага назад. Среди попыток преодолеть эту проблему имеются и такие, которые походя решают и нашу "русскую" задачу.
Что мы имеем сегодня? Идиотизм положения с кодировками здесь налицо - классический русский камень на распутье у каждого сайта: "выберите вашу кодировку". Это совершенно ненормальная ситуация. Приходится дублировать (растраивать и учетверять) содержимое, повышая вероятность ошибок и ляпов, причем такое решение рождает больше вопросов, чем ответов. Как поступать, например, с заполнением форм (интерактивных опросных листов) или server-parsed HTML (с макроподстановками) и др.?Из современных альтернативных решений можно привести два:
перекодировка базовой страницы "на лету" при помощи выбранного CGI-script (то есть программы, выполняющейся на сервере); автоматическое определение требуемой кодировки по запросу.
В общем, ни одно из них не удовлетворительно, хотя и удобнее простого дублирования. Первое грешит некоторыми неудобствами в использовании и увеличением времени доступа. Второе не всегда выполнимо, так как основывается на том, что локальный браузер передает на сервер некоторую информацию о себе, включающую иногда и тип платформы/операционной системы, что не всегда верно и не гарантирует наличия у пользователя шрифтов в нужной кодировке.
Следует принимать во внимание, что количество пользователей, работающих исключительно с электронной почтой, будет неуклонно уменьшаться, а число on-line-пользователей будет постоянно расти. И таким пользователям потребуются дополнительные услуги и, естественно, лучшее качество отображения и разнообразный сервис. Нынешний пользователь российской сети - это в основном программист (около трех четвертей, по некоторым опросам), а они, как известно, неприхотливые, грязные, ленивые и неряшливые. До тех пор, пока в "паутину" не попадут гуманитарии (в том числе и полиграфисты, художники и дизайнеры), сдвигов в лучшую сторону не будет.
Поэтому будем ориентироваться, как всегда, на запад (и преимущественно - "дикий", то есть американский), где это уже случилось (а по некоторым тенденциям, и у нас не за горами). Такому пользователю вряд ли объяснишь про "обрезание" восьмого бита, а вот неряшливую верстку, ошибки и "кривые" шрифты он сразу заметит. Где выход?Их пока два:
верстка и сохранение Web-страниц в PDF-формате (Adobe Acrobat); использование Web-шрифтов, отправляемых вместе с документом и CSS-расширений HTML.
Про PDF- формат особенно распространятся не буду, хотя, с моей точки зрения, это лучший выход (не зависящий ни от кодировки и языка, ни от платформы и операционной системы). К сожалению, фирма Adobe "проспала" волну Интернета, и хотя Acrobat-файлы поддерживаются многими Web-браузерами (обычно существует соответствующий plug-in), они не становятся стандартом.
CSS-расширения напоминают древние стадии развития языков программирования и средств разработки (как и в целом Интернет, при всей новизне своих технологий, постоянно напоминает что-то архаичное - то в одной своей части, то в другой). Желающие могут ознакомиться с ними на W3, а нам это показалось временной мерой (а может быть, и "мертворожденной").
Web-шрифты на страже русской язычности
Итак, в Интернет пришли гуманитарии. HTML-документы эволюционируют от простых <HR> и 3D-кнопок к профессиональным, хорошо оформленным страничкам, цель которых - привлечь и удержать посетителей-непрограммистов. Одним из важнейших недостатков нынешних средств разработки Web-страниц, с точки зрения полиграфистов, явилось отсутствие возможности жесткой установки шрифта, вследствие чего дизайнер не может быть уверен в том, что клиент увидит на экране именно то, что им было задумано.
Наилучшим решением, гарантирующим правильность и качество шрифтов, считается сегодня встраивание их непосредственно в Web-документы и передача пользователю (обычно только для просмотра). Предлагается использовать оба основных типа шрифтов: TrueType и PostScript. Шрифты TrueType при надлежащем хинтовании позволяют получить более качественное изображение на экране, а PostScript-шрифты, будучи производственным стандартом в издательском деле, обеспечивают качественную печать.
Использование встраиваемых шрифтов сдерживается лишь увеличением размера HTML-файла и, как следствие, продолжительностью передачи при сохранении достойного качества воспроизведения.
До последнего времени указывать конкретные шрифты в HTML было практически невозможно. Дизайнер выбирал шрифт, включал его в определение Web-страницы, а пользователь, не имеющий такого шрифта на своей машине, лицезрел тот, который автоматически (по умолчанию) подставлял браузер (в нашем, русском случае, браузер мог подставить шрифт, в котором вообще нет русских букв). Даже сами пользователи не всегда могли изменить умолчания, заложенные в браузерах, и результат еще дальше уходил от проектирования (если вообще сохранялся). Многие, конечно, использовали графическое представление текста, но это приводило к довольно громоздким файлам, которые к тому же не читались текстовыми браузерами (такими, например, как Lynx). При встраивании шрифта в документ эти проблемы устраняются. Пользователь увидит именно те шрифты, которые были заложены при проектировании, даже если они не установлены на его компьютере. Ведущие изготовители браузеров объявили о программной поддержке встроенных шрифтов.
Другое преимущество встроенных шрифтов - достигаемое качество при отображении и печати (это особенно актуально для больших документов, которые трудно читать с экрана). При посылке шрифта вместе с документом в него включается вся информация о символах, включая хинтование и другие средства шрифта, применяемые его создателями для улучшения качества отображения и печати. Причем планируется передавать только те символы, которые были использованы в документе (подмножество шрифта), что обеспечит дополнительную экономию.
Дальнейшее уменьшение размеров передаваемых файлов может быть обеспечено дополнительной компрессией (сжатием и по возможности без потерь). По мере того как в подготовке публикаций на Web участвуют все более творческие люди, к тому же не понимающие коммуникационных проблем, размеры файлов будут постоянно расти.
Для того чтобы использовать подмножество шрифта, необходимо, чтобы приложения, используемые при создании документа, поддерживали этот метод. Microsoft Office 97 имеет такую возможность, позволяет встраивать шрифты в документ, проверять документ на вхождение в него шрифтов и ассоциировать зашифрованную версию шрифта с документом. Некоторые шрифты не будут допускать встраивание в документ, и на них указанная возможность не будет распространяться. Когда такой документ с легально встроенными шрифтами придет по назначению, они будут расшифрованы.
Программные средства сжатия шрифтов основываются на технологиях Agfa MicroType Express и Adobe CFF, обеспечивающих сжатие без потери качества. MicroType Express работает со шрифтами TrueType и PostScript, а CFF только со шрифтами PostScript. Сжатие средствами Agfa полностью сохраняет информацию оригинала и в сочетании с методом передачи подмножества шрифта обеспечивает 90-процентное сжатие для шрифтов на основе латинской графики и до 99 процентов - для китайского, корейского и "нам" подобных. В отличие от методов "сжатия с потерями", применяемыми при хранении изображений и фильмов, технология MicroType Express сохраняет полное соответствие исходных литер и их вида на страницах Интернета, поддерживая декомпрессию "на лету". При этом сохраняются и все хинты, что обеспечивает высокое качество отображения и печати. Microsoft Internet Explorer обязался поддерживать эти технологии.
Open Type
Компании Microsoft и Adobe совместно работают над новым универсальным шрифтовым форматом под названием Open Type, сочетающим в себе TrueType и PostScript. Частью создаваемой технологии является и сжатие шрифтов. В Open Type будет усовершенствовано управление существующими шрифтами и создан формат, который обеспечит работу с новым поколением компьютерных шрифтов, рассчитанных на Web-использование. Существенная часть этой работы посвящена кросс-лицензированию шрифтов, а также технологии, которая обеспечит работу обоих форматов с разными платформами. Формат Open Type обеспечит встраивание шрифтов TrueType или PostScript в документ и простую процедуру инсталляции и использования проектировщиками и пользователями Web-страниц. Microsoft объявила о намерении сделать шрифты Open Type стандартным элементом своей базовой операционной системы. Adobe собирается поддерживать Open Type в новых версиях своих программных продуктов для графических, издательских и Интернет-приложений.
Перспектива превращения Open Type в новую архитектуру шрифтов для издательской деятельности во "Всемирной паутине" символизирует окончание ведущейся сейчас "шрифтовой войны". Поскольку такие лидеры в деле информационных технологий, как Agfa, Adobe и Microsoft обязались улучшить качество передачи текста на Интернете вообще и WWW в частности, новая технология использования подмножеств, сжатия и встраивания шрифтов в HTML-документы имеет несомненное будущее. Способность сохранять информацию, содержащуюся в шрифте, и качественно ее воспроизводить обеспечит Web-страницы гарантированным соблюдением стиля и дизайна, а нас, "русскоговорящих", освободит от обязанности поддерживать кодировки на все случаи нашей излишне разнообразной жизни.
Тенденции же перевода и передачи электронной корреспонденции в HTML-формате сведут на нет и все "почтовые" проблемы. Таким образом, можно с уверенностью заявить: владельцы серверов - руки прочь от всевозможных перекодировок, ваш "скорбный труд" все равно пропадет всуе!
По "Всемирной паутине", не снимая тапочек
- рТЙЧЕФ. лБЛ ДЕМБ?
- Da normal'no, a u tebja?
Из разговора
Здравствуйте, уважаемый пользователь! Представляем вам глобальную сеть Интернет. Здесь вы найдете все, что вам только может понадобиться. Пользоваться Интернетом проще простого: устанавливаете программы, полученные от вашего поставщика услуг Интернета, запускаете браузер (он же броузер, он же смотрелка, он же бродилка), дозваниваетесь поставщику и попадаете на его сервер. Изучив содержимое сервера, вы обнаруживаете гиперссылку на страницу анекдотов (например, http://www.kulichki.com/anekdot/), которая находится на другом сервере. "О! Анекдоты!" - думаете вы и, предвкушая удовольствие, щелчком перемещаетесь на другой сервер. Страница с анекдотами медленно появляется на вашем мониторе. Позвольте... А где же анекдоты? Это не анекдоты. Это набор греческих или каких-то других значков. Вероятно, какая-то ошибка на их сервере. Вы возвращаетесь к поставщику и находите ссылку на страницу политических новостей. "Ну, как там Чубайс?" - думаете вы, загружая новости. После чего оказывается, что Чубайс отныне говорит на смеси английского и непонятно какого еще языка, состоящего из прописных букв русского алфавита. Вы застываете в недоумении. Почему у поставщика на сервере все по-русски, а у остальных - нет?..
Ведущие разработчики программного обеспечения сосредотачивают свои усилия в области WWW-средств и мультимедиа, ясно показывая нам, чего следует ожидать в этой области в недалеком будущем.
Однако в результате непрерывной "войны браузеров" потери в первую очередь несет потребитель. Увеличиваются требования к производительности компьютеров (главным образом - к памяти), усложняются программы, появляется новое оборудование. Все эти средства предназначаются в основном "техноэлите". Таким образом, теряется огромное количество потенциальных пользователей. А нынешним клиентам Сети при каждом обращении необходимо перерабатывать "тонны угля", чтобы в результате получить мифический "алмаз", доступный далеко не каждому.
Телевизионный Web-терминал (WebTV), напротив, - такое же простое устройство, как видеомагнитофон или телефонный автоответчик. На обычном пульте управления добавляется только одна кнопка - WEB. Я не упомянул бы о приставках WebTV, если бы не обнаружил их присутствие уже и в России.
Применение Web-телевизоров сегодня сдерживается в основном неразвитой инфраструктурой сети и слабыми средствами коммуникаций (особенно в нашей стране). Для массовой передачи информации требуется принципиально иная пропускная способность каналов связи, современное оборудование и простое в обращении программное обеспечение. Однако вспомните: еще год назад перегружать Web-странички большим количеством картинок считалось дурным тоном и неуважением к пользователю, а теперь скорость связи даже по обычным линиям возросла настолько, что стали возможны переговоры голосом по Интернету, и телефонные компании начинают серьезно беспокоиться за свое будущее.
Возможно, главным подходом к использованию WebTV в ближайшее время будет передача текстовой информации, конференций (например, по "мыльным операм"), одиночных изображений и фрагментов видео с отсроченным просмотром.
Реальное использование WebTV во всем мире ограничивается сегодня немногими приложениями: новостями по требованию (включая погоду и спортивные результаты), обозрением кинофильмов, передач и телевизионных программ, а также коммерческими заказами. Успех будет зависеть, вероятно, от того, насколько просто зрители будут получать такую информацию и насколько удобным будет обращение к Интернет-ресурсам. Большинство людей были бы счастливы пользоваться телевизором вместо компьютера, если цена на дополнительное оборудование не окажется слишком высокой (сейчас она составляет около 300-400 долларов за устройство), а работа будет достаточно удобной. Электронная почта - главная возможность, которая выведет WebTV на массовый рынок в ближайшем будущем.
В любом случае, WebTV - это другая среда использования Интернета, поскольку основными "пользователями" телевизоров являются бабушки, дедушки, дети и домохозяйки. Придется приспосабливаться и к их нуждам.
Каким образом, господа провайдеры, вы объясните им необходимость KOI8-R? - О.Т.
Ya v AustraliY i ottuda tebe privet !
prejnyaya stranichka tchitalasy cherez KOI8. A chto mne s novoy sdelaty? okolo 40 statey po russkim fontam prochel........Pochemu ne dogovoritesy pabotaty s odnoy kodirovkoy. Drug, my vse jelaem chitaty smotrety vashy sayty.
RASKAJI KAK VY USTRAIVAETESY S KODIROVKAMIY, POJALUYSTA!!!!!!!!!!!!!!!!
Телефон редакции: (095) 232-2261
E-mail редакции: site@computerra.ru
По вопросам размещения рекламы обращаться к Алене Шагиной по телефону +7 (095) 232-2263 или электронной почте reclama@computerra.ru
Кристоф Шпиль [Christoph Spiel]
Крис руководит расположенной в Верхней Баварии (Германия) компанией, консультирующей по вопросам Open Source Software. Не смотря на то, что по образованию он физик (он получил ученую степень Доктора Философии в Мюнхенском Технологическом Университете), его главные интересы вращаются вокруг численных методов, гетерогенных сред программирования и разработки программного обеспечения. Связаться с ним можно по адресу cspiel@hammersmith-consulting.com.
Copyright (C) 2002, Christoph Spiel.
Copying license http://www.linuxgazette.com/copying.html
Published in Issue 75 of Linux Gazette, February 2002
Команда переводчиков:
Владимир Меренков, Александр Михайлов, Иван Песин, Сергей Скороходов, Александр Саввин, Роман Шумихин, Александр Куприн
Со всеми предложениями, идеями и комментариями обращайтесь к Сергею Скороходову (). Убедительная просьба: указывайте сразу, не возражаете ли Вы против публикации Ваших отзывов в рассылке.
Сайт рассылки: http://gazette.linux.ru.net
Эту статью можно взять здесь: http://gazette/linux.ru.net/lg75/articles/rus-spiel.html
Крис руководит расположенной в Верхней Баварии (Германия) компанией, консультирующей по вопросам Open Source Software. Не смотря на то, что по образованию он физик (он получил ученую степень Доктора Философии в Мюнхенском Технологическом Университете), его главные интересы вращаются вокруг численных методов, гетерогенных сред программирования и разработки программного обеспечения. Связаться с ним можно по адресу cspiel@hammersmith-consulting.com.
Крис руководит расположенной в Верхней Баварии (Германия) компанией, консультирующей по вопросам Open Source Software. Не смотря на то, что по образованию он физик (он получил ученую степень Доктора Философии в Мюнхенском Технологическом Университете), его главные интересы вращаются вокруг численных методов, гетерогенных сред программирования и разработки программного обеспечения. Связаться с ним можно по адресу cspiel@hammersmith-consulting.com.
Крис руководит расположенной в Верхней Баварии (Германия) компанией, консультирующей по вопросам Open Source Software. Не смотря на то, что по образованию он физик (он получил ученую степень Доктора Философии в Мюнхенском Технологическом Университете), его главные интересы вращаются вокруг численных методов, гетерогенных сред программирования и разработки программного обеспечения. Связаться с ним можно по адресу cspiel@hammersmith-consulting.com.
Copyright (С) 2001, Christoph Spiel.
Copying license http://www.linuxgazette.com/copying.html
Published in Issue 73 of Linux Gazette, December 2001
Команда переводчиков:
Владимир Меренков, Александр Михайлов, Иван Песин, Сергей Скороходов, Александр Саввин, Роман Шумихин
Со всеми предложениями, идеями и комментариями обращайтесь к Сергею Скороходову (suralis-s@mtu-net.ru)
Сайт рассылки:
Кто занимается стандартизацией locale ?
Изначально стандарт на средства POSIX locale был заявлен Международной организацией по Стандартизации и в составе стандарта POSIX ( Portable Operating System Interface for Computer Environments ):
POSIX.1 (ISO/IEC 9945-1:1988) - Интерфейс
POSIX.2 (ISO/IEC 9945-2:1998) - Команды и утилиты
Позднее он был принят комитетом как IEEE Std. 1003.1-1990 а позже введен в стандарт ANSI C ( ISO 9899:1990 ).
В дальнейшем, в позднейших выпусках POSIX
:
POSIX.1 ( ISO/IEC 9945-1:1992, он же IEEE Std. 1003.1-1992)
POSIX.2 ( ISO/IES 9945-2:1992, он же IEEE Std. 1003.2-1992)
и в выпусках 1994 и 1996 г.г. дополненных POSIX.2a, POSIX.2b, стандартный набор средств для локализации был расширен, сделан более переносимым и был более документирован.
Свой вклад в развитие localе
внесla также , образовав Joint Internationalization Group (JIG) и выпустив документы XPG2, XPG3, XPG4 (X/Open Portability Guide) включающие в себя также главы о локализации :
XPG2 : X/Open Portability Guide, Volume 2, January 1987, XVS System Calls and Libraries (ISBN: 0-444-70175-3).
XPG3 : X/Open Specification, February 1992, System Interfaces and Headers, Issue 3 (ISBN: 1-872630-37-5, C212); this specification was formerly X/Open Portability Guide, Issue 3, Volume 2, January 1989, XSI System Interface and Headers (ISBN: 0-13-685843-0, XO/XPG/89/003).
XPG4 : X/Open CAE Specification, July 1992, System Interfaces and Headers, Issue 4 (ISBN: 1-872630-47-2, C202).
В настоящее время происходит постепенный переход на стандарт POSIX 1996 и сосуществуют самые различные реализации, включающие в себя элементы как старого POSIX 1988, так и нового POSIX
1996 в той или иной мере.
Практически все современные коммерческие реализации Unix-ов имеют полную реализацию стандартов POSIX.1 (вызовов) и POSIX.2
(утилит) версии 1996 (в отношении locale).
Из Free реализаций наиболее известны две : 4.4BSD Lite libc и GNU libc
(получившая дальнейшее развитие в ) также поддерживающие POSIX 1996 .
В недалеком будущем возможно включение в стандарты локализации стандарта (16-битныx символов) и возможности работы с ними.
В других операцонных системах, таких как Windows NT, Windows'95, OS/2 Warp, Nowell Netware и т.д. также существуют средства локализации, в общих чертах повторяющие средства локализации POSIX.
Language
Информация, полученная из "человеческого" мира и предназначенная для машинной обработки, как правило имеет специальный арибут : язык или language (lang). Причем, не только текстовая, но например audio :
Content-Description: Russian Argo audio sample :-) Content-Type: audio/basic Content-Language: ru
(, )
Однако нас инересует именно текстовая
информация.
Большинство языков мира имеют письменнось, а некоторые языки даже несколько (например кириллица и глаголица для славянских языков или kana и kanji в японском и т.д.). Определенная система письменности называется script. Системы письменности существуют самые разнообразные (например узелковое :-), но большинство письменностей - это изображение
последовательности специальных символов
(character).
* ПРИМЕЧАНИЕ : Объяснение концепции символа
выходит далеко за рамки данного документа. Мы не будем вдаваться в филологические и философские подробности, а рассмотрим лишь узкий аспект -- способы представления символов
(национального) языка для автоматической (машинной) обработки. Тогда термин "символ" (character) можно определить как "единицу текстовой информации" (unit of textual information), которая передается письменно и участвует в машинной обрабоке. Очень важно четко представлять себе, что речь идет об "абстрактном"
символе.
Language Modes
Как уже говорилось, под этим подразумевается язык не человеческий, а программистский. И список поддерживаемых режимов включает, не считая чисто текстового (Plain), почти все известные мне (и многие неизвестные) языки программирования и разметки. Здесь и C и C++, Java и JavaScript, Ada, Fortran, Pascal, Python, Tcl, awk, языки командных оболочек линии bash и линии csh, языки разметки SGML/HTML и LaTeX, PostScript, SQL и прочая, и прочая, и прочая. Разумеется, есть и режим собственного языка NEdit Macro.
Первое видимое следствие переключения языкового режима - появление подсветки синтаксиса соответствующего языка (если, конечно, эта опция включена, о чем - ниже). Так, по умолчанию в NEdit задействован режим Plain text. В этом случае. скажем, тэги в html-документе, подобном данному, показываются теми же черными (для примера) буквами), что и его содержание. Если же переключиться в режим SGML/HTML, тэги, их аргументы и значения последних заиграют различными цветами. Впрочем, при открытии файла определение его типа обычно происходит автоматически, по расширению (и обычно - правильно), и соответствующий языковый режим включается сам собой.
Однако различие между языковыми режимами не исчерпывается цветовой гаммой. Многие макросы (о которых - в следующем разделе) имеют языковую привязку. И появляются в меню Macro только тогда, когда включается соотвествующий их языку режим.
Разумеется, подсветка синтаксиса необходима в первую очередь программистам. Хотя и всем прочим, хоть иногда просматривающим исходники web-страниц, тоже не вредит. А вот следующая группа настроек
LaTeX
Позвольте мне сначало рассказать, что такое LaTeX и с какими целями он создавался. LaTeX -- это огромный пакет дополнительных макросов для системы предпечатной типографской подготовки TeX, созданной профессоромДоналдом Кнутом. Если не слишком придираться, то говоря "система LaTeX" или просто "LaTeX", мы будем иметь в виду "TeX плюс все макросы LaTeX". Собственно LaTeX был написан Лесли Лэмпортом [Laslie Lamport], который решил, что хотя TeX и очень могуч, но его слишком сложно использовать для повседневных задач. За основу он взял систему Scribe. Scribe делает упор на логическую структуру документа вместо физической разметки (для тех читателей, которые хорошо разбираются в HTML добавлю, что тэг <em> является примером логической разметки, а тэг <i> -- соответствующей ей физической разметки).
LaTeX -- как и классический plain TeX -- позволяет на обычном компьютере создавать, готовить для печати и распечатывать документы с полиграфическим качеством оформления. Замысел был таков: автор готовит статьи или даже книги на своем личном компьютере, а затем относит дискету в полиграфический салон для того, чтобы документ был распечатан на фотонаборной машине высокого разрешения, и, наконец, получает переплетенную книгу (... затем рассылает ее во все книжные магазины квадранта альфа, делает на этом миллионы, а через два года получает Межгалактическую Пулицеровскую премию. -- ну хорошо, я несколько преувеличиваю:).
В последующих раздела я изложу очень короткое введение в LaTeX, но всем, кто хочет изучить LaTeX, я бы рекомендовал Не столь краткое введение в LaTeX [Not So Short Introduction to LaTeX]. Этот 95-страничный документ можно бесплатно скачать из Сети: смотрите в .
LaTeX устанавливается вместес большинс твом современных Linux-дистрибутивов. Проверить правильность его установки можно с помощью команды:
latex --version
Моя система отзывается на нее так:
TeX (Web2C 7.3.1) 3.14159 kpathsea version 3.3.1 Copyright (C) 1999 D.E. Knuth. Kpathsea is copyright (C) 1999 Free Software Foundation, Inc. There is NO warranty. Redistribution of this software is covered by the terms of both the TeX copyright and the GNU General Public License. For more information about these matters, see the files named COPYING and the TeX source. Primary author of TeX: D.E. Knuth. Kpathsea written by Karl Berry and others.
Latex2html
Пока все нормально. LaTeX позволяет подготовить великолепно выглядящие документы на Postscript'е, а "единоутробная" утилита pdf делает то же самое, но в переносимом формате документов. Разве мы не говорили, что нам нужет и HTML тоже? Конечно говорили! Но тут LaTeX нам не помощник, для этого нам нужен другой инструмент: latex2html. Эта утилита преобразует исходные файлы LaTeX в набор html-файлов, связанные гиперссылками в соответствии со структурой исходного документа.
Загрузить latex2html можно с его домашней страницы: http://www.latex2html.org. Можно взять его и на , а лучше с одного из зеркал. Для того, чтобы выяснить, установлен ли latex2html в вашей системе выполните команду:
latex2html --version
должно быть что-то вроде этого:
This is LaTeX2HTML Version 2K.1beta (1.57) by Nikos Drakos, Computer Based Learning Unit, University of Leeds.
Что следует изменить для того, чтобы сделать документы LaTeX пригодными для обработки latex2html? Хорошая новость -- почти ничего! Убедитесь, что в преамбуле указаны пакеты html и makeindex, т.е. как минимум добавьте следующее
\usepackage{html,makeidx}
в преамбулу вашего документа. Теперь файл my_document.tex может быть преобразован в HTML следующим вызовом
latex2html my_document.tex
LDP
Проект Linux Documentation Project (LDP) был начат с целью предоставить новым пользователям быстрый путь получения информации о конкретном предмете. Он не только содержит серию книг о администрировании, работе в сетях и программировании, но и огромное число небольших работ, посвященных конкретным проблемам, написанных теми кто сталкивался с ними. Например, если вы хотите узнать о печати,возмите Printing HOWTO. Если хотите знать как работает ваша Enthernet карта под Линукс,возмите Enthernet HOWTO и так далее. Первоначально многие из этих работ были в текстовом или HTML формате. Но с течение времени стало ясно, что должен существовать лучший путь хранения и обработки этих документов. Путь, который позволил бы вам читать документ с веб страницы, в виде текстового файла на CD-ROM, или даже на карманном PDA. И ответ был найден - SGML.
Лингвистика и компютеры.
Журнал "Multilingual Communications & Technology"
Журнал "Language Today"
Журнал "Communications of COLIPS"
Yamada Language Center
Human-Languages Page - каталог Internet ресурсов
Еще подборка ссылок :
Japanese Computing
Understanding Yiddish Information Processing
Croatian language / Hrvatski jezik
South Asian Scripts on the Web
Linux :
Linux Cyrillic-HOWTO от Alexander L. Belikoff .
(чуть-чуть устарел)
Дает массу полезной информации по русификации дисплея и клавиатуры,
включению 8-bit в различных программах и использованию русских шрифтов.
Перевод Cyrillic-HOWTO (V3.15, 14 ноября 1997) Евгения Балдина :
(еще более устаревшая версия...)
Linux Ukrainian HOWTO
Другие национальные Linux HOWTO :
Linux Locales mini-HOWTO by Peeter Joot, <>
c
Дает быстрый способ установки locale на машину.
Страничка Boris Tobotras <> посвященная Linux-у
Страничка Dmitri Beloslioudtsev <> - автора русской NLS Linux libc
( home: ) и его коллекция locales, charmaps и NLS :
ЛИСП
M-x load-file / library Загрузить файл с ЛИСПОМ .elc, .el M-x byte-compile-file Откомпилировать файл То же из Shella: emacs -batch -f batch-byte-compile FILES... M-x byte-recompile-directory Перекомпилировать файлы в директории M-x disassemble Декомпиляция ЛИСП-функции M-x insert-kbd-makro Вставить описание функции Last-modified: Sun, 31 Aug 1997 19:11:09 GMT
LISP - язык программирования Emacs.
Более серьезные настройки в редакторе Emacs осуществляются через написание процедур на языке LISP. Например, чтобы присвоить какой-либо клавише выполнение определенной команды, нужно вставить в конфигурационный файл строку, написанную на LISPе.
В языке программирования LISP, также как и в C, все определяется через функции. Можно использовать свои собственные функции, или библиотеки функций, написанных другими пользователями, - пакеты, чтобы настроить работу Emacs. PSGML - пакет, разработанный на LISPе. Однако, прежде, чем устанавливать PSGML, разберемся с более простыми случаями установки LISP-функций.
Все LISP-функции запускаются из файла .emacs.
ПРИМЕЧАНИЕ: Поскольку DOS не поддерживает длинные имена файлов, то версии Emacs под DOS и 16-bit MS Windows используют для автоматического запуска функций файл с именем _emacs.
Поначалу синтаксис новых функций, помещаемых в файл .emacs можно копировать у уже существующих функций, заменяя нужные места в названиях и командах. Поясним это на примере. Команда goto-line вызывается при нажатии комбинации M-g. Соответствующая функция в файле .emacs выглядит следующим образом:
| (global-set-key "\eg" 'goto-line) ; M-g prompts for line number to enter |
Обычно команда goto-line не имеет комбинации клавиш, поэтому в таком редакторе нужно сначала нажать M-x, а затем из командной строки запустить команду goto-line. У программистов и пользователей SGML часто возникает необходимость перейти в строку с определенным номером, поэтому целесообразно вместо команды использовать комбинацию клавиш.
Если комбинация M-g не определена, то добавьте приведенную выше строку в файл .emacs, сохраните файл и перезапустите Emacs. Теперь при нажатии M-g в окне минибуфера появится сообщение:
| Goto line: |
После ввода номера строки редактор перейдет в указанную строку.
Другая популярная команда многих текстовых процессоров - overwrite-mode, которая переключает режим ввода текста между insert (Вставка) и replace (Забой). Пользователь, работающий с текстом скорее всего предпочтет работать в режиме вставки, чем каждый раз для перевода в режим Забоя вводить четырнадцатибуквенную команду. Целесообразно отредактировать файл .emacs, добавив в него строку, присваивающую комбинации M-i выполнение команды overwrite-mode. Воспользуемся в качестве заготовки строкой, определяющей комбинацию M-g.
Команда LISP, которая присваивает комбинации клавиш некую функцию Emacs - global-set-key. Эта команда имеет два параметра: комбинацию клавиш и присваиваемую ей команду. Клавиша Escape обозначается через "\e". Таким образом, комбинация M-i будет выглядит в LISPe "\ei". Следует помнить, также, что перед присваиваемой командой должна стоять одиночная кавычка "'" (это означает в LISP, что присваиваемая команда - символьное выражение). И последнее, символом комментария в LISP является ";", игнорируется все, что идет после этого знака.
Итак, строка в файле .emacs, которая присваивает комбинации клавиш M-i выполнение команды overwrite-mode выглядит следующим образом:
| (global-set-key "\ei" 'overwrite-mode) ; toggle overwrite mode |
| (global-set-key "^T" 'kill-word) ; enter ^T here with C-q C-t |
Локализация и почта. MIME.
Вместо введения - кусок перевода :
MIME - Multi-purpose Internet Mail Extensions. Свободно-доступный набор спецификаций, предлагающий способ обмена текстами с различным набором символов и multimedia e-mail среди множества различных компьютерных систем, которые используют стандарты Internet для обмена почтой.
Если Вы уже имели дело с обычной текстовой электронной почтой, теперь, благодаря MIME
Вы можете создавать и читать сообщения, имеющие следующие дополнительные возможности :
Символы, отличные от US-ASCII
Форматированный (enriched) текст
Изображения
Звуки
Другие сообщения (включенные одно в другое)
Архивные файлы
PostScript файлы
Указатели на местоположение файлов
другие возможности
MIME поддерживает не только некоторые, раз и навсегда заданные типы нетекстовой информации, например 8-bit 8000Hz-sampled mu-LAW audio, или GIF images, или PostScript-программы, но и позволяет Вам также определять Ваши собственные типы данных.
Перед тем, как стандарт MIME
стал широко распространенным, у Вас также была возможность создавать сообщения, содержащие, скажем, PostScript документы и звуковое сопровождение, но чаще всего сообщение было закодировано в собственном, не переносимом формате. Это означало, что Вы не могли прочитать это сообщение на системе от другого поставщика, даже если оно прошло неповрежденным через почтовый шлюз. Теперь же, в зависимости от совершенства Вашей MIME почтовой системы, есть неплохой шанс, что это будет "просто работать".
Самое ценное в MIME то, что это "четырехколесный протокол". Протокол MIME
был аккуратно разработан для выживания в среде самых разнообразных SMTP, UUCP и других Procrustean протоколов передачи почты, которые любят перемешивать, перепутывать и перекодировать заголовки и текст почтового сообщения.
. . .
Стандарт MIME определен в :
| : | MIME Part One: Format of Internet Message Bodies |
| : | MIME Part Two: Media Types |
| : | MIME Part Three: Message Header Extensions for Non-ASCII Text |
| : | MIME Part Four: Registration Procedures |
| : | MIME Part Five: Conformance Criteria and Examples |
Или см. напрмер на Yahoo! :
Для пользователя здесь выигрыш в том, что у сообщения (или части сообщения) типа text/plain,
text/html появился параметр charset=Xxxxx
, однозначно задающий кодировку сообщения. Если charset= не проставлен, кодировка предполагается ISO_8859-1
(набор символов Latin-1).
Другое полезное свойство MIME
- закодированные заголовки. Дело в том, что стандартный RFC-822 предполагал, что заголоки писем From: , To: и т.д. 7-ми битные. Для обхода этой проблемы была предложена схема MIME. И теперь заголовки могут иметь вид :
Subject: Re: =?KOI8-R?Q?=C1?=
Предположим теперь, что наша операционная система - UNIX (POSIX). Здесь мы имеем дело с 3-мя различными объектами:
Установленное значение locale (LANG="...").
Текущие фонты и раскладка клавиатуры терминала (аппаратные).
Кодировка почтового сообщения charset=xxxxx MIME.
Само по себе, текущее значение locale
( установленное через LANG=) ( а точнее значение категорий LC_CTYPE и LC_COLLATE
) оказывает влияние только на обработку
символов, но никак не на ввод/вывод.
Как мы уже знаем, средствами locale
и стандартного UNIX никак нельзя ни повлиять, ни даже спросить
текущее значение аппаратной
конфигурации (кодировки).
С другой стороны, почтовые сообщения в MIME могут содержать различные даже в пределах одного сообщения.
Задача почтовой программы (MUA
- Mail User Agent)-- правильно отобразить различные charset для text/plain и text/html. Это легко сделать в оконных системах (Windows, X-Windows, e.t.c.) где доступна информация о шрифтах, но невозможно
для стандартного UNIX терминального .
В наиболее старой и известной программе для работы с MIME - (взять можно ) впервые столкнулись с данной проблемой. Именно для была впервые введена переменная окружения MM_CHARSET
которая задавала "текущий" charset
(набор символов) на консоли. Предполагалось, что пользователь его знает (или сам установил). Но постепенно эта переменная стала трактоваться как значение текущей кодировки аппаратного окружения (фонтов, e.t.c.) и современные почтовые программы (mh, elm) активно используют эту переменную.
Любая современная почтовая программа должна обязательно поддерживать UNICODE
и UTF-8. См. : Internet Mail Consortium / .
Содержание ""
Last change : 08-10-1999
Локализация и POSIX.
Если мы говорим о файле, то в идеологии POSIX, - это просто плоская последовательность байтов. Внутреннее содержимое не стандартизовано никак. Поэтому невозможно определить, какую информацию содержит файл, а если он содержит текстовую информацию -- в какой она кодировке. То же самое можно сказать о потоках : stdin/stdout
-- это потоки байтов (кодов). Кодировка (т.е. соответствие символ-код (CES)) полностью потеряна и нигде не указывается. И POSIX
вовсе не гарантирует, что CES (кодировка) stdin
будет совпадать с текущей локализацией, заданной через LANG=.
Точно тактая же ситуация с терминальным : кодировка терминала совершенно неизвестна приложению.
К сожалению, в стандарте POSIX
поддержка Charset не имеет полностью идеологически стройной и ясной концепции. Понятие Charset существует только для locale API и тех функций, которые зависят от locale.
Более того, в "чистом" POSIX
вообще невозможно
узнать (получить) имя Charset после вызова . Единственный способ, узнать Charset текущей locale
- это воспользоваться не-POSIX функцией XPG
(но определенной в Single UNIX, SVID
и Unix98) : (определена в файле ). Тогда текущий Сharset можно получить так :
| #include <locale.h> #include <langinfo.h>
... setlocale(LC_ALL,""); printf ("Current charset = %s\n",nl_langinfo(CODESET)); |
Надо ли говорить, что некоторые UNIX
(например ) не имеют этих XPG-extensions и не имеют функции как таковой вообще. (Что очень странно, поскольку в том же POSIX определена утилита c keyword-ом codeset которая "как-то" это имя определяет...) Например, популярная система до сих пор не имеет функции (как впрочем не имеет и утилиты , увы !).
Еще один способ определения текущего Charset-а - это разбор
переменной окружения . По стандарту POSIX переменная LANG=
задается в форме LANG=language_TERRITORY.Codeset. Например, переменная
(управляющая поведением подсистемы )может иметь "подстановки" :
%L
The value of the LC_MESSAGES category.
%l
The language element from the LC_MESSAGES category.
%t
The territory element from the LC_MESSAGES category.
%c
The codeset element from the LC_MESSAGES category.
Таким образом, если задать LANG="ru_RU.KOI8-R", то мы получим :
%L
= "ru_RU.KOI8-R"
%l
= "ru"
%t
= "RU"
%c
= "KOI8-R"
Исходные тексты этих функций открыты и широко доступны.
Таким образом, установив LANG=ru_RU.KOI8-R
мы получим сообщения на русском языке в кодировке KOI8-R, а установив LANG=ru_RU.ISO_8859-5
- в кодировке ISO. На некоторых системах точно так же работает переменная MANPATH=.
К сожалению, поле Charset - опционально и по стандарту можно использовать сокращенную форму : LANG=ru_RU или даже LANG=ru. (См. ключ -f ). Поэтому, если ваша система это поддерживает, задавайте максимально длинное имя для LANG=
, указывая Charset. (получить список можно по ). К сожалению, само тоже может различаться.
Довольно значительное число ошибок происходит из за того, что в языке С
определен тип переменных char (хотя точнее было бы назвать его : byte). Это во-первых, жестко привязывает нас к 8-ми битным кодировкам. А во-вторых, кодировка не определена. Поэтому, если мы задаем строку (массив char), в которой употребляются символы не ASCII (с кодами >128) : char string[]="Проверка"; -- результат совершенно непредсказуем и непереносим. Еще больше проблем вызывает идея .
Также вызывает удивление существование (и синтаксическая корректность) типов signed / unsigned char (что такое "отрицательный" символ? Вот unsigned short int
-- понятно)... Если вы планируете работу вашей программы в многоязычном окружении, неплохо бы предусмотреть атрибут Сharset у любой строки символов char *. Или полностью переходить на UNICODE (wchar_t) в качестве внутренней кодировки.
Содержание ""
Last change : 02-11-1999
Локализация, интернационализация, глобализация.
Так уж сложилось, что языком разработчиков вычислительных машин был английский язык. ;-)
По мере распространения компьютеров и (ПО) программного обеспечения для них по всему миру, постепенно стала нарастать потребность в обработке информации не только на английском, но и на других - немецком, японском, русском, e.t.c. -- национальных языках.
Потребность в такой многоязыковой поддержке ощущали как пользователи
программного обеспечения - для решения своих конкретных задач, так и производители
ПО - для расширения рынков сбыта.
Таким образом сложилась идея инернационализации
( internationalization, или сокращенно i18n
) программных продуктов.
Термин интернационализация
( i18n ) подразумевает под собой такой способ проектирования ( дизайн ) ПО, при котором возможность многоязыковой поддержки закладывается с самого начала.
Самым желательным вариантом реализации многоязыковой поддержки является такой, при котором нацонально-зависимая
часть приложения хранится отдельно от приложений в виде набора данных : объектов локализации. При этом возможность гибкого и простого изменения языкового окружения под конкретные требования происходит без перекомпиляции этих приложений.
Таким образом, локализация ( localization, или сокращенно l10n ) - это процесс адаптации ПО под конкретные национальные требования . А технически, локализация - это изготовление отдельных объектов локализации в соответствии c требованиями конкретного языка.
Локализация, как она есть.
Hа правах v0.59 Alpha версии, сильно глюкаво. Исправления ожидаются и принимаются.
Последние изменения : 13-04-2000.
Локализация (l10n), интернационализация (i18n) :
The Languages of the World by Computers and the Internet
All the scripts of the World
Internationalization (Взгляд американских военных на проблему)
Локализация в слайдах :
Internationalization Issue, by Michael K. Gschwind <>
Internationalization (i18n) and Localization (l10n). Коллекция ссылок :
Internationalization concept dictionary (Cловарь по i18n)
Glossary of Global Development Terms (Словарь терминов)
Internationalization / Localization (w3c)
Borneo: Internationalization and Localization
Поддержка интернационализации на платформе Java.
Локализация от Microsoft.
Фирма уделяет значительное внимание локализации продуктов и захвате национальных рынков программного обеспечения. Первый европейский офис был открыт в 1982 г. В мае 1983 г. была выпущена операционная система MS-DOS 2.1 с поддержкой японского языка для компьютеров IBM 5550 и NEC PC-9801.
Стоит также сказать, что ожидаемая операционная система Windows 2000 (Windows NT 5.0) будет иметь полную поддержку UNICODE, от файловой системы до шрифтов и Notepad. Кроме того, она будет содержать классическую схему локализации : будет разделен исполняемый код и национально-зависимые части. Вся информация, имеющая отношение к "национальной специфике" будет вынесена в "объекты локализации". Таким образом, национальные версии будут отличаться только небольшим числом файлов.
Наиболее полное описание модели локализации от Microsoft можно найти в книге Nadine Kano : "Developing International Software for Windows 95 and Windows NT". Эта книга есть на MSDN.
LyX
Необязательно -
LyX сочетает мощь SGML с простотой использования обычного ворд-процессора.Но это не WYSIWYG программа, а WYSIWYM (What You See Is What You Mean - "То-Что-Ты-Видишь-Это-То-Что-Ты-Имел-Ввиду") приложение,т.к. то что вы видите на экране это не обязательно то , что будет видеть пользователь после обработки вашего документа SGML процессором. То как LyX отображает документ, похоже на то как визуализирует его Jade, но не полностью. Хотя достаточно близко, чтобы представить себе как будет выглядеть документ. Секции и под-секции пронумерованы и выделены жирным шрифтом, для представления таких вещей как тэги <code> и <url> используются разные шрифты. Большинство тэгов спрятано от вас во время редактирования, т.к. LyX пишет в TeX,а затем экспортирует TeX в SGML.
посвященные разного рода текстовым процессорам
Автор: Алексей Крюков, basileia@yandex.ru
Опубликовано: 20.03.2002
Оригинал: http://www.softerra.ru/freeos/16826/
Статьи, посвященные разного рода текстовым процессорам под Linux, традиционно принято начинать с общих рассуждений о назначении и пользе данного класса программ. И для этого есть серьезные основания. Ведь первое и естественное желание, возникающее у Windows-мигранта, впервые обратившегося к Linux, заключается в том, чтобы продолжить работу со своими данными, представленными, скорее всего, в текстовой форме. Начиная поиск подходящего софта, пользователь видит перед собой несколько облегченных редакторов (которым, соответственно, для серьезной научной работы – грош цена), а также монументальный StarOffice, до сих пор не способный нормально работать с русскими текстами. Ныне это положение меняется благодаря активной разработке проекта OpenOffice.org и ожидаемому StarOffice 6.0. И всё же принудительная сила реальности заставляет признать, что Linux традиционно ориентирован на подготовку файлов в простом текстовом формате, а вовсе не на работу с документами в режиме WYSIWYG.
Данное явление может оцениваться по-разному. Можно, конечно, в совершенстве освоить какой-нибудь текстовый редактор и после этого свысока поглядывать на пользователей текстовых процессоров, неспособных избавиться от привычки злоупотреблять оформительскими эффектами. Увы, практика показывает, что некоторые элементы оформления текста необходимо вносить уже на этапе его ввода. Скажем, выделение полужирным и курсивом часто несет смысловую нагрузку. Ну а если речь идет о тексте научном, то в нем наверняка понадобятся подстрочные примечания и таблицы. И еще хуже, если придется ссылаться на иностранную литературу: тогда не обойтись без совмещения в одном документе нескольких кодовых страниц, каковое, естественно, потребует смены шрифтов.
Таким образом, единственным выходом из положения становится подготовка документов на языках текстовой разметки (TeX и HTML), позволяющих задать нужные элементы форматирования в виде тегов. Однако изучение языка разметки требует определенных усилий, и не всякому пользователю дается легко. К тому же не всем приходится составлять многостраничные оригинал-макеты. Сочинять же служебное письмо со справочником по командам LaTeX на коленях – занятие едва ли осмысленное. Вот тут-то и приходит на помощь текстовый процессор LyX, представляющий собой уникальную попытку соединить одно из основных достоинств Linux – интеграцию с системой LaTeX с возможностью подготовки документов в визуальном режиме.
По LyX существуют неплохие руководства на русском языке. Это труды и Алексея Федорчука, послужившие отправной точкой при написании этой статьи. Но, во-первых, развитие LyX не стоит на месте, и некоторые рекомендации этих авторов, скажем так, слегка устарели. А во-вторых, их работы – это, прежде всего, руководства по русификации, построенные по принципу: делай так-то – получишь такой-то результат. Я же хотел бы подробнее описать сам механизм взаимодействия LyX с LaTeX, так, чтобы, во-первых, стал ясен внутренний смысл практических действий по начальной настройке программы, и, во-вторых, чтобы пользователю легче было понять, в каком случае LyX действительно может облегчить его работу, а в каком – проще заняться написанием исходников LaTeX напрямую.
Итак, LyX – это не что иное, как графическая надстройка над системой LaTeX, наличие которой в установленном виде необходимо для его нормального функционирования. И если открыть подготовленный в LyX файл в простом текстовом редакторе, можно увидеть нечто внешне сходное с исходником LaTeX. На это как будто указывает знак backslash, с которого начинаются все команды. Однако же аргументы этих команд не заключаются в фигурные скобки, а просто отделяются пробелом, да и в качестве знака комментария используется символ # (а не %, как в LaTeX). Кроме того, странное впечатление производит структура текста с многочисленными переносами строк: с новой строки начинается каждая команда. И лишь когда мы дадим команду распечатать текст (или просмотреть DVI или postscript), программа в качестве промежуточного этапа сгенерирует настоящий документ LaTeX (файл с расширением .tex), который при желании можно будет разыскать где-то в недрах каталога /tmp.
Для чего же понадобилось создавать специальный язык разметки, нужный только как переходный этап? На этот вопрос легко ответить всякому, кому приходилось видеть html-код, сгенерированный визуальными редакторами. Этот ход оттого и получается неудобочитаемым, что такие редакторы стремятся «на лету» исполнять команды пользователя, не пытаясь воссоздать их внутреннюю логику. А ведь язык LaTeX значительно сложнее, чем html, и последствия могут быть хуже. Приведу такой пример. Для пометки текста на иностранном языке в LaTeX обычно используются команды-декларации \selectlanguage{}. Такая команда будет действовать до появления следующей декларации, отменяющей ее, например:
Русский текст. \selectlanguage{english} Some text in English. \selectlanguage{russian} Снова русский текст.
Однако можно сделать и по-иному, заключив команду переключения языка в фигурные скобки вместе с относящимся к ней текстом, так, чтобы она действовала только на него:
Русский текст. {\selectlanguage{english} Some text in English.} Снова русский текст.
Очевидно, что первый способ предпочтительнее для выделения целых абзацев текста, второй же – для фрагментов в несколько слов. Ясно также, что программе куда легче оценить объем каждого отрывка при компиляции текста для печати, чем пытаться судить о намерениях пользователя в процессе редактирования. Так вот, LyX прекрасно справляется с этой задачей, так что в данном конкретном случае к расставленным им командам LaTeX сложно придраться самому строгому критику. Ну а для того, чтобы обеспечить сохранение данных в процессе работы, как раз и нужен упрощенный язык разметки, по возможности снимающий все разночтения, подобные описанному выше. Преобразование своего внутреннего формата в документ LaTeX, по существу, является основной задачей программы, и потому львиная доля настроек LyX связана именно с регулированием этого процесса.
LyX и LinuxDoc
Один из доступных стилей в LyX SGML(LinuxDoc). Его можно использовать, чтобы читать и писать документы из LinuxDoc документации. Чтобы прочитать SGML документ, он должен быть переведен сначала в LyX формат с помощью утилиты sgml2lyx. Чтобы сделать sgml документ, просто выберите стиль SGML из окна стилей документов и вставьте название и автора (они обязательны), а потом просто пишите тело документа.
В этом режиме LyX не показывает все возможности редактирования,а только те что поддерживаются LinuxDoc.
Существуют строгие взаимоотношения между LyX и LinuxDoc, достаточно сказать, что sgml2lyx утилита в пакете sgml-tools и не в дистибутиве LyX. Также, SGML документация в пакете sgml-tools, среди всех форматов, также и в формате LyX.
Macro
Этот пункт разделяется на две секции. Первая, стабильная, предназначена для создания и запуска пользовательских макрокоманд. В ней можно видеть:
включение режима протоколирования макросов (Learn Keystrokes, Alt+K); нормальное завершение (Finish Learn, повторное Alt+K) и прерывание (Cansel Learn, Ctrl+.) протоколирования; воспроизведение (Replay Keystrokes, Ctrl+K) и повторение (Repeat, Ctrl+.) запротоколированных макрокоманд.
Вторая секция - настраиваемая, в нее можно включить макрокоманды, как идущие в комплекте, так и созданные собственоручно. Например, с помощью протоколирования - иначе они не сохраняться по завершении текущего сеанса.
В комплекте с той версией NEdit, которая имеется в моем распоряжении, идут макросы для:
дополнения частично напечатанных слов путем сопоставления их со словарем (Complete Word, Alt+D), некий Fill Sel v/Char (из комментариев в теле макроса я не очень понял, что это, к тому же пункт этот не активизирован) ответы на письма - с цитированием (Quote Mail Reply) и без оного (Unquote Mail Reply)
Кроме того, имеется серия языково-зависимых макросов, предназначенных для программирования на C++. Они появляются в меню только при включении соответствующего языкового режима. Однако, как и в случае с Shell, не видно причин, по которым нельзя было бы исключить из меню заведомо не нужные макросы, заменив их собственными. Именно это и будет темой заключительных разделов саги.
А пока посмотрим, что же такое понимается в NEdit под пунктом
Мая 2002 года
Последняя версия (3.11) была выпущена в конце 1998 года. За это время появилось много разных конверторов кодировок на любой вкус. Я не вижу смысла в дальнейшем развитии rusconv, так как она программа содержит большинство необходимых функций, а всё остальное можно сделать с помощью набора скриптов.
За три года существования программы свои отзывы прислали более полусотни пользователей, общее впечатление - благоприятное. Сообщений об ошибках прислано не было, но это не означает, что их нет. Я обнаружил следующее:
Временные файлы (в unix-версии) создаются с помощью небезопасной функции "mktemp". Теоретически злоумышленник может испортить данные пользователя. При перезаписи файла теряются исходные права доступа. В windows 95 использование маски "*.*" приводит к ошибке - имена файлов дублируются. Один раз имя файла возвращается как есть, а во второй раз - в формате 8.3. Не поддерживается буква "ё" (jo) в кодировке koi8 (много лет назад её не следовало использовать).
Эти неточности уже никогда не будут исправлены, по крайней мере, мной. Начиная с 2002 года весь пакет (программа, исходники, документация и прочее) распространяется по лицензии public domain. Вы можете делать с ним всё, что хотите, в том числе и исправлять ошибки. Для поддержки буквы "ё" выпущен патч . Его нужно скопировать в папку с исходными текстами и перекомпилировать программу. Файл содержит досовские концы строк, под Unix'ом, возможно, для некоторых компиляторов придётся преобразовать их в обычные.
Если вам хочется использовать не rusconv, а что-то другое, то рекомендую обратить внимание на iconv и . Программа iconv является стандартной для Linux'a и большинства Unix'ов. Она знает практически все существующие кодировки. Утилита enca пытается автоматически определять язык и кодировку данных. Обе программы портированы под windows и другие операционные системы.
htpp://uucode.com/rusconv/index.html
Oleg A. Paraschenko <olpa uucode com>
Majordomo
Под русификацией Majordomo мы подразумеваем приведение сообщений, отправляемых Majordomo, в ответ на запросы к такому виду, чтобы почтовый клиент не строил догадок относительно кодировки сообщения, а точно знал ее. Патч, который можно взять , предназначен для Majordomo 1.94.5 и устанавливает кодировку сообщений в koi8-r.
Make Backup Copy и Sort Open Prev. Menu
Это также простые переключатели. Первый разрешает или запрещает создание резервных копий редактируемого файла. Включение его приводит к тому, что при перезаписи измененного документа предыдущая его версия сохраняется в виде файла с расширением *.bck.
С помощью Sort Open Prev. Menu можно включить алфавитную сортировку ранее открывавшихся файлов, входящих в список File - Open Previous. При выключении этой опции файлы в нем следуют в хоронологическом порядке.
Осталось рассмотреть лишь немногие настройки Preferences, такие, как
МАКРОКОМАНДЫ И Т.П.
^u <команда> Выполнить команду n раз (n - число) M-x <функция> Выполнить функцию по имени M-x set-variable Установить значение переменной M-x global-set-key <функция> Повесить на клавишу функцию. ^X ( клавиши ^X ) задать макрокоманду ^X e выполнить макрокоманду name-last-kbd-makro присвоить ей имя insert-last-kbd-makro воспроизвести клавиши LISP кода insert-kbd-makro вставить lisp-код по функции. M-x disassemble дизассемблировать функцию.
Макросы
Существует полезная команда редактора ex для редактора vi - abbreviate. Она используется для сокращения наиболее часто применяемых фраз. Синтаксис команды : :ab string thing to substitute for. Например : если вам необходимо вводить слово "Humuhumunukunukuapua`a", но вы не хотите каждый раз набирать его полностью - используйте команду ab. Для данного случая она будет выглядеть так :
:ab 9u Humuhumunukunukuapua`a
Теперь если вы введете 9u - вы получите полное значение. При вводе 9university замены не произойдет.
Для удаления сокращения используется команда unabbreviate. Для данного случая - :una 9u. Команда :ab выдаст список всех сокращений.
Другая полезная команда редактора ex - map. Существуют две разновидности команды - для командного режима и для режима вставки текста - map и map! соответственно. Работает сходно с командой ab - последовательность символов заменяется обычно командами редактора vi.
Манипулирование символьно/строковым форматированием
~ Изменить регистр символа в позиции курсора. < Выполнить сдвиг влево на величину shiftwidth. "<<" - сдвиг текущей строки влево (использует аргумент count). > Выполнить сдвиг вправо на величину shiftwidth. ">>" - сдвиг текущей строки вправо (использует аргумент count). J Объединить текущую строку с последующей. Аргумент count определяет количество строк.
Manual
rusconv v.3.11.
Руководство пользователя.
Назначение.
Программа rusconv служит для преобразования русскоязычных текстов - перевода их в кодировки: альтернативную (кодовая страница 866, для DOS), koi8 (для UNIX и Русской Сети), Windows (кодовая страница 1251), Macintosh и latinica (russkij tekst latinskimi bukvami). Возможен перевод из DOS/windows-формата текстовых файлов в UNIX-формат и обратно. Один файл можно переводить сразу в несколько кодировок, можно переводить сразу несколько файлов. Разработан для использования из командной строки и из командных файлов. Windows-версия понимает длинные имена файлов и сетевые файлы.
Описание.
Способы запуска:
rusconv (-h|--help) rusconv [options] -(alt|koi|mac|win) +(alt|koi|mac|lat|win) [--] <file_list> [output_dir] rusconv [options] -(cr2crlf|crlf2cr) [--] <file_list> [output_dir] rusconv [options] -(dos2unix|win2unix|unix2dos|unix2win|d2u|w2u|u2d|u2w) [--] <file_list> [output_dir]
1. rusconv (-h|--help)
Выводит на экран текст помощи.
2. rusconv [options] -(alt|koi|mac|win) +(alt|koi|mac|lat|win) [--] <file_list> [output_dir]
Программа переводит содержимое файлов в списке <file_list>
из кодировки -xxx в кодировку +xxx. Результаты сохраняются в файлах с теми же именами, но с другими расширениями. Они создаются в директории [output_dir], либо, если выходная директория не задана, в текущем каталоге.
Необходимо указывать ровно одну кодировку, из которой надо переводить. Для этого используются флаги:
флаг кодировка
-alt - альтернативная (DOS) -koi - КОИ-8 (UNIX) -mac - Macintosh -win - Windows
Можно переводить сразу в несколько кодировок. Для этого надо дать не менее одного из флагов:
флаг кодировка
+alt - альтернативная (DOS) +koi - КОИ-8 (UNIX) +lat - latinica +mac - Macintosh +win - Windows
По умолчанию к именам файлам добавляются такие расширения:
расширение для кодировки
.alt - альтернативной (DOS) .koi - КОИ-8 (UNIX) .lat - latinica .mac - Macintosh .win - Windows
Чтобы задать свои расширения для файлов с результатами перевода, используйте команды:
расширение для файлов, содержащих текст в кодировке
-aext расширение - альтернативной (DOS) -kext расширение - КОИ-8 (UNIX) -lext расширение - latinica -mext расширение - Macintosh -wext расширение - Windows
При переводе только в одну кодировку можно использовать команду
-ext расширение
В зависимости от кодировки, в которую происходит преобразование, это воспринимается как одна из команд '-aext расширение', '-kext расширение', '-lext расширение', '-mext расширение' или '-wext расширение'.
Флаг '-o' используется для перезаписывания. Вместо того чтобы создавать новые файлы, rusconv изменяет содержимое переводимых файлов.
Кроме преобразования кодировок, rusconv позволяет изменять тип строк. В DOS и windows конец строки кодируется двумя символами, в UNIX - одним. Для перевода из одного формата в другой предназначены флаги
-cr2crlf - из UNIX-формата текстовых файлов в DOS/windows-формат -crlf2cr - из DOS/windows-формата текстовых файлов в UNIX-формат
DOS и windows-версии по умолчанию разговорчивые. В UNIX-версии по умолчанию выводятся только предупреждения и сообщения об ошибках. Чтобы задать режим работы, используйте флаги
'-s' - работа без вывода на экран любых сообщений '-v' - вывод на экран всех сообщений
Операционная система windows запускает rusconv в отдельном окне, которое должно закрываться после окончания программы. Чтобы окно не закрывалось, и пользователь мог просмотреть отчет о проделанной работе, rusconv после перевода всех файлов ждет нажатия любой клавиши. Поведение можно изменить с помощью флагов
'-close' - завершаться сразу после окончания перевода файлов '-noclose' - не закрывать окно с отчетом, по умолчанию
Флаги '-close' и '-noclose' имеют смысл только в windows-версии. В DOS и UNIX-версиях они игнорируются.
Сочетание символов '--' служит для указания конца флагов. Все, что стоит после него, является списком файлов.
3. rusconv [options] -(cr2crlf|crlf2cr) [--] <file_list> [output_dir]
В данном случае изменяется только тип строк, преобразования кодировок не происходит. В DOS и windows конец строки кодируется двумя символами, в UNIX - одним.
-cr2crlf - из UNIX-формата текстовых файлов в DOS/windows-формат -crlf2cr - из DOS/windows-формата текстовых файлов в UNIX-формат
Расширения по умолчанию для создаваемых файлов:
расширение формат текстового файла
.cr - UNIX-формат .crlf - DOS/windows-формат .crl - DOS/windows-формат, используется в DOS-версии
Для установки своего расширения можно дать команду
-ext расширение
Остальные флаги используются аналогично пункту '2'.
4. rusconv [options] -(dos2unix|win2unix|unix2dos|unix2win|d2u|w2u|u2d|u2w) [--] <file_list> [output_dir]
Для полноценного переноса русских файлов между наиболее популярными операционными системами достаточно использовать флаги
-dos2unix (или -d2u) - из DOS в UNIX -win2unix (или -w2u) - из Windows в UNIX -unix2dos (или -u2d) - из UNIX в DOS -unix2win (или -u2w) - из UNIX в Windows
Они являются всего лишь сокращениями. При разборе командной строки они заменяются:
-dos2unix (или -d2u) на '-alt +koi -crlf2cr'
-win2unix (или -w2u) на '-win +koi -crlf2cr'
-unix2dos (или -u2d) на '-koi +alt -cr2crlf'
-unix2win (или -u2w) на '-koi +win -cr2crlf'
Примеры использования.
1. Пример для windows.
Файлы file1.txt и file2.txt из кодировки КОИ-8 переводятся во все остальные кодировки. Результат сохраняется в файлах с именами file1.alt, file1.koi, file1.lat, file1.mac, file1.win, file2.alt, file2.koi, file2.lat, file2.mac, file2.win в директории e:\txt.
E:\EX>rusconv -koi +alt +koi +win +mac +lat file1.txt file2.txt e:\txt\ ** rusconv -- convertor of Russian codepages, v.3.11. ** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/ .\file1.txt -> e:\txt\file1.alt, e:\txt\file1.koi, e:\txt\file1.mac, e:\txt\file1.lat, e:\txt\file1.win: ok. .\file2.txt -> e:\txt\file2.alt, e:\txt\file2.koi, e:\txt\file2.mac, e:\txt\file2.lat, e:\txt\file2.win: ok. 2 file(s) converted.
2. Пример для windows.
Тип концов строк текстовых сетевых файлов \\server\d\files\*.txt
преобразуется из UNIX-формата в DOS/windows-формат.
E:\EX>rusconv -cr2crlf -o \\server\d\files\*.txt ** rusconv -- convertor of Russian codepages, v.3.11. ** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/ \\server\d\files\EC-1845.TXT -> \\server\d\files\rcB180.TMP -> \\server\d\files\EC-1845.TXT: ok. \\server\d\files\HUMOR_PR.TXT -> \\server\d\files\rcB181.TMP -> \\server\d\files\HUMOR_PR.TXT: ok. \\server\d\files\NON_PAS.TXT -> \\server\d\files\rcB183.TMP -> \\server\d\files\NON_PAS.TXT: ok. 3 file(s) converted.
3. Пример для UNIX.
Содержимое .html-файлов из директории win/
переводится из windows-версии русского текста в UNIX-версию. Результат сохраняется в файлах с теми же именами в директории koi/.
rusconv -v -win2unix -ext html win/*.html koi/ ** rusconv -- convertor of Russian codepages, v.3.11. ** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/ win/faq.html -> koi/faq.html: ok. win/feedback.html -> koi/feedback.html: ok. win/index.html -> koi/index.html: ok. 3 file(s) converted.
Код возврата.
Количество переведенных файлов.
manual.html
Документ создан Паращенко Олегом
Последние изменения - 15 ноября 1998 года
Manual-e
rusconv v.3.11 manual
Description.
Rusconv is intended for converting text between russian encodings: alternative (for DOS, codepage 866), KOI-8 (for UNIX), Macintosh, Windows (codepage 1251) and latinica (russian text spelled latin letters). Rusconv also can convert from DOS/windows text file format to UNIX one and back. Files can be converted to several encodings simultaneously, any number of files can be converted simultaneously. Designed for use from command line and from command scripts. Windows version supports long file names and local network files.
Synopsys.
rusconv (-h|--help) rusconv [options] -(alt|koi|mac|win) +(alt|koi|mac|lat|win) [--] <file_list> [output_dir] rusconv [options] -(cr2crlf|crlf2cr) [--] <file_list> [output_dir] rusconv [options] -(dos2unix|win2unix|unix2dos|unix2win|d2u|w2u|u2d|u2w) [--] <file_list> [output_dir]
1. rusconv (-h|--help)
Prints help.
2. rusconv [options] -(alt|koi|mac|win) +(alt|koi|mac|lat|win) [--] <file_list> [output_dir]
Program converts content of files in <file_list>
from encoding -xxx to encoding +xxx. Results are placed in files with the same names but with another extensions. Files are created in directory [output_dir], or in current one if output directory is not specified.
You should specify one and only one encoding from which to convert:
flag encoding
-alt - alternative (DOS) -koi - KOI-8 (UNIX) -mac - Macintosh -win - Windows
You can specify several encodings to convert to:
flag encoding
+alt - alternative (DOS) +koi - KOI-8 (UNIX) +lat - latinica +mac - Macintosh +win - Windows
Default extensions are:
extension for encoding
.alt - alternative (DOS) .koi - KOI-8 (UNIX) .lat - latinica .mac - Macintosh .win - Windows
To specify you own extensions for files with convert results use commands:
extension for files contained text in encoding
-aext extension - alternative (DOS) -kext extension - KOI-8 (UNIX) -lext extension - latinica -mext extension - Macintosh -wext extension - Windows
When converting to only one encoding you can use command
-ext extension
Depending on encoding to which you convert it is interpreted as one of command '-aext extension', '-kext extension', '-lext extension', '-mext extension' or '-wext extension'.
Flag '-o' is used for overwriting. Instead of creating new files rusconv changes content of existing files.
Rusconv also can convert from DOS/windows text file format to UNIX one and back. In DOS and windows end of line is coded by two chars, in UNIX - by one char. For converting from one format to another use flags
-cr2crlf - from UNIX text file format to DOS/windows one -crlf2cr - from DOS/windows text file format to UNIX one
DOS and windows versions are verbose by default. UNIX version prints only warnings and error messages. To redefine default mode use flags
'-s' - silent work, no any message will be printed '-v' - verbose work, all messages will be printed
Windows operating system runs rusconv in separate window which should be closed after program finished. To avoid this and to let user to see report rusconv after all files converted waits for key pressed. Behavior can be changed by flags
'-close' - to finish after all files converted '-noclose' - do not close window with report, by default
Flags '-close' and '-noclose' are used only in windows version. DOS and UNIX versions ignore them.
Symbols '--' stands for 'end of flag'. All after this symbols is a file list.
3. rusconv [options] -(cr2crlf|crlf2cr) [--] <file_list> [output_dir]
In this case rusconv converts only type of lines and doesn't convert from one encoding to another. In DOS and windows end of line coded by two chars, in UNIX - by one char.
-cr2crlf - from UNIX text file format to DOS/windows one -crlf2cr - from DOS/windows text file format to UNIX one
Default extensions for files are:
extension text file format
.cr - UNIX type .crlf - DOS/windows type .crl - DOS/windows type (used in DOS version)
To specify you own extension use command
-ext extension
Other flags are used as in section '2'.
4. rusconv [options] -(dos2unix|win2unix|unix2dos|unix2win|d2u|w2u|u2d|u2w) [--] <file_list> [output_dir]
For most often tasks - converting general russian text from DOS to UNIX, from Windows to UNIX and back - it is enough only one flag:
-dos2unix (or -d2u) - from DOS to UNIX -win2unix (or -w2u) - from Windows to UNIX -unix2dos (or -u2d) - from UNIX to DOS -unix2win (or -u2w) - from UNIX to Windows
This flags are abbreviations. During command line parsing they are replaced by:
-dos2unix (or -d2u) by '-alt +koi -crlf2cr'
-win2unix (or -w2u) by '-win +koi -crlf2cr'
-unix2dos (or -u2d) by '-koi +alt -cr2crlf'
-unix2win (or -u2w) by '-koi +win -cr2crlf'
Examples.
1. Example for windows.
Files file1.txt and file2.txt are converted from encoding KOI-8 to all other encodings. Results are placed in files file1.alt, file1.koi, file1.lat, file1.mac, file1.win, file2.alt, file2.koi, file2.lat, file2.mac, file2.win in directory e:\txt.
E:\EX>rusconv -koi +alt +koi +win +mac +lat file1.txt file2.txt e:\txt\ ** rusconv -- convertor of Russian codepages, v.3.11. ** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/ .\file1.txt -> e:\txt\file1.alt, e:\txt\file1.koi, e:\txt\file1.mac, e:\txt\file1.lat, e:\txt\file1.win: ok. .\file2.txt -> e:\txt\file2.alt, e:\txt\file2.koi, e:\txt\file2.mac, e:\txt\file2.lat, e:\txt\file2.win: ok. 2 file(s) converted.
2. Example for windows.
Type of lines of text network files \\server\d\files\*.txt is converted from UNIX format to DOS/windows format.
E:\EX>rusconv -cr2crlf -o \\server\d\files\*.txt ** rusconv -- convertor of Russian codepages, v.3.11. ** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/ \\server\d\files\EC-1845.TXT -> \\server\d\files\rcB180.TMP -> \\server\d\files\EC-1845.TXT: ok. \\server\d\files\HUMOR_PR.TXT -> \\server\d\files\rcB181.TMP -> \\server\d\files\HUMOR_PR.TXT: ok. \\server\d\files\NON_PAS.TXT -> \\server\d\files\rcB183.TMP -> \\server\d\files\NON_PAS.TXT: ok. 3 file(s) converted.
3. Example for UNIX.
Content of .html-files in directory win/
is converted from windows style of russian text to UNIX style. Results are placed in files with the same name in directory koi/.
rusconv -v -win2unix -ext html win/*.html koi/ ** rusconv -- convertor of Russian codepages, v.3.11. ** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/ win/faq.html -> koi/faq.html: ok. win/feedback.html -> koi/feedback.html: ok. win/index.html -> koi/index.html: ok. 3 file(s) converted.
Return code.
Number of converted files.
manual-e.html
Document created by Oleg A. Paraschenko
Last changes - 15 November 1998
Массивы
Допускается использование массивов. Массивы не объявляются, а принимают значения из контекста, например:
x[NR] = $0 - элементу массива x, индексированному NR, присваивается обрабатываемая строка.
x["apple"] - элементы массива могут индексироваться не числовым значением, т.е. строкой.
Математические выражения.
В txt2html есть две возможности для записи математических символов и выражений. The system used is the standard LaTeX mode surrounded by %equation delimeters. Например, выражение

создано так:
%equation
E = m c^2
%equation
as txt2html parses your file, it will extract the latex source and generate a gif file from it. This is then automatically placed as an image in your resulting html file.
Создание выражений без текста также возможно с помощью %math команд. Например, следующее выражение:
Знаменитая формула Эйнштейна

создано так:
Знаменитая формула Эйнштейна
%math E = m c^2 %math
описывает взаимосвяз материи и энергии.
Обратите внимание, что выравнивание здесь происходит не по правому краю. Любые предложения о том, как это исправить, приветствуются.
МЕч-чяшпАБЛ
аБЮчзп рщьвЦ ДЮуыэп (ъчт АБЮчзчы Юужьэп) щпвКрпуБАО МЕч-чяшпАБЛН. +щп ьАъчшЛвЦуБАО тшО ъчзпвп щуячшЛХьЕ ДЮпсэущБчр БузАБп р щуАзчшЛзьЕ ФушОЕ.
мЕч чячвщпГпуБ чБчяЮпжущьу щпяьЮпуэКЕ рпэь вщпзчр. ¦щу Emacs, чъуЮпФьчщщпО АьАБуэп чяКГщч чБчяЮпжпуБ руАЛ рпХ ррчт. Emacs ЦъЮпршОуБ МЕч ьщпГу.
Emacs щьзчстп щу ъчрБчЮОуБ зчэпщтК, АчАБчОИьу ьв чтьщчГщчсч вщпзп, п зчэпщтК, АчАБчОИьу ьв щуАзчшЛзьЕ, ъчрБчЮОНБАО, БчшЛзч уАшь рК чАБпщпршьрпуБуАЛ р ъЮчФуААу ьЕ щпячЮп. ¦пз БчшЛзч рК чАБпщпршьрпуБуАЛ ячшуу Гуэ щп АузЦщтЦ р АуЮутьщу зчэпщтК, рАу вщпзь МБчы зчэпщтК АЮпвЦ жу чБчяЮпжпНБАО. мБч АшЦжьБ ъчтАзпвзчы тшО чзчщГпщьО зчэпщтК. ¦пз БчшЛзч рзшНГпуБАО МЕч, чзчщГпщьу зчэпщтК чБчяЮпжпуБАО щуэутшущщч р ъЮчФуААу щпячЮп. бпзчу ъчрутущьу ъЮутщпвщпГущч тшО Бчсч, ГБчяК ЦруЮущщКы ъчшЛвчрпБушЛ ъчшЦГпш яКАБЮКы ЮувЦшЛБпБ, р Бч жу рЮуэО МБч ъчврчшОуБ щуЦруЮущщКэ ъчшЛвчрпБушОэ ъчшЦГьБЛ эпзАьэЦэ чяЮпБщчы АрОвь. ¦К эчжуБу ьвэущьБЛ МБч ъчрутущьу, ЦАБпщчрьр чАчяЦН ъуЮуэущщЦН (АэчБЮьБу Юпвтуш ).
¦Ашь зчэпщтп щу эчжуБ яКБЛ рКъчшщущп, чщп р ъуГпБпуБ МЕч-чяшпАБь АччяИущьу чя чХьязу. аччяИущьу чя чХьязу АчъЮчрчжтпуБАО врЦзчрКэ Аьсщпшчэ ьшь эьспщьуэ МзЮпщп. ¦Ючэу Бчсч, зчстп ъЮчьвчХшп чХьязп, шНячы щпяЮпщщКы ъуЮут МБьэ ррчт АяЮпАКрпуБАО.
+узчБчЮКу зчэпщтК ъуГпБпНБ р МЕч-чяшпАБь ьщДчЮэпФьчщщКу АччяИущьО. +щь ъчЕчжь щп АччяИущьО чя чХьязпЕ, щч яув врЦзчрчсч Аьсщпшп, ь щпяЮпщщпО Юпщуу ьщДчЮэпФьО щу АяЮпАКрпуБАО. Tщчстп МБь АччяИущьО счрчЮОБ рпэ, ГБч зчэпщтп рКъчшщущп, р АшЦГпу, уАшь МБч Орщч щу щпяшНтпуБАО ъЮь ъЮчАэчБЮу ЮутпзБьЮЦуэчсч БузАБп. Tщчстп утьщАБрущщчы ФушЛН зчэпщтК ОршОуБАО ъуГпБЛ АччяИущьО, тпНИусч рпэ АъуФьДьГуАзЦН ьщДчЮэпФьН. +пъЮьэуЮ, зчэпщтп а-Е = ьАъчшЛвЦуБАО, ГБчяК щпъуГпБпБЛ АччяИущьу, чъьАКрпНИуу ъчвьФьН БчГзь р БузАБу ь уу БузЦИьы АБчшяуФ р чзщу. ¦чэпщтК, БЮуяЦНИьу тшО Арчусч рКъчшщущьО тшьБушЛщчу рЮуэО, ГпАБч рКрчтОБ рч рЮуэО ЮпячБК АччяИущьО, впзпщГьрпНИьуАО щп `...', п р зчщФу, зчстп чщь впзчщГьшьАЛ, Ашчрч `done'.
TщДчЮэпБьрщКу АччяИущьО ьв МЕч-чяшпАБь АчЕЮпщОНБАО р яЦДуЮу, щпвКрпуэчэ `*Messages*'. (+К уИу щу чяЙОАщьшь, ГБч Бпзчу яЦДуЮ; тшО ъчшЦГущьО ячшЛХуы ьщДчЮэпФьь ч щьЕ АэчБЮьБу Юпвтуш .) ¦Ашь рК ъЮчъЦАБьшь АччяИущьу, зчБчЮчу щутчшсч чБчяЮпжпшчАЛ щп МзЮпщу, рК эчжуБу ъуЮузшНГьБЛАО р яЦДуЮ `*Messages*' ь Ащчрп ъчАэчБЮуБЛ усч. (©чАшутчрпБушЛщКу АччяИущьО ч ъЮчэужЦБчГщКЕ ЮувЦшЛБпБпЕ ГпАБч АрчЮпГьрпНБАО р МБчэ яЦДуЮу р чтщч.)
юпвэуЮ яЦДуЮп `*Messages*' чсЮпщьГущ чъЮутушущщКэ ГьАшчэ АБЮчз, МБч ГьАшч вптпуБ ъуЮуэущщпО message-log-max. ¦пз БчшЛзч яЦДуЮ тчЮпАБпуБ тч МБчсч ЮпвэуЮп, зпжтпО щчрпО АБЮчзп ЦтпшОуБ чтщЦ АБЮчзЦ ьв щпГпшп. аэчБЮьБу Юпвтуш , ГБчяК ЦвщпБЛ, зпз ЦАБпщчрьБЛ ъуЮуэущщКу, Бпзьу зпз message-log-max.
мЕч-чяшпАБЛ ьАъчшЛвЦуБАО Бпзжу тшО чБчяЮпжущьО эьщьяЦДуЮп: чзщп, зчБчЮчу ьАъчшЛвЦуБАО тшО АГьБКрпщьО пЮсЦэущБчр тшО зчэпщт, щпъЮьэуЮ, ьэущь Дпышп тшО ЮутпзБьЮчрпщьО. ¦чстп ьАъчшЛвЦуБАО эьщьяЦДуЮ, МЕч-чяшпАБЛ щпГьщпуБАО Ач АБЮчзь ъчтАзпвзь, зчБчЮпО чяКГщч зчщГпуБАО трчуБчГьуэ; зЮчэу Бчсч, р МБчы АБЮчзу ъчОршОуБАО зЦЮАчЮ, Бпз зпз чщп АБпщчрьБАО рКяЮпщщКэ чзщчэ. ¦К рАустп эчжуБу рКыБь ьв эьщьяЦДуЮп, щпяЮпр C-g. аэчБЮьБу Юпвтуш .
Mg - emacs-like text editor
Чтобы заставить mg работать с русскими буквами, достаточно создать файл ~/.mg, содержащий строчку:
meta-key-mode
MIME :
MIME FAQ из USENET группы comp.mail.mime :
или то же в HTML :
MIME Overview, by Mark Grand
The Internet Mail Consortium [Inernationalization]
MIME RFC: RFC-2045..2049
Многооконное редактирование
Редактировать сразу несколько файлов можно либо пользуясь командной редактора :e filename, либо указав все необходимые файлы в командной строке при вызове редактора (например: vi file1 file2 file3). В последнем случае вы двигаетесь по списку файлов с помощью команд:
:n - переходим к следующему файлу в списке
:rew - возвращаемся к редактированию первого файла в списке
Именованные буферы сохраняют свое содержимое при переходе к редактированию другого файла.
Модифицирующие клавиши
Ctrl: в сочетании с другими клавишами расширяет сферу их применения. Например, нажатие клавишщи Home перемещает курсор в начало строки, тогда как в сочетании с нажатием клавиши Ctrl (то есть Ctrl+Home - в начало документа.
Shift: расширяет выделение относительно позиции курсора при нажатии клавиш управления последним (аналогично действию клавиши Shift в Windows).
Alt: используется, в частности, для выделения колонок и прямоугольных фрагментов. (For the effects of modifier keys on mouse button presses, see the section titled "Using the Mouse")
"MOVA" --- скрипты для работы со словарями в формате "MOVA"
Предлагаемые скрипты используйте на условиях GNU GPL.
Скрипты используют стандартные утилиты UNIX - grep, sed, fmt, а для работы в консоли еще и groff, less. Они проводят поиск в текстовом файле и выводят найденные строчки в графическую оболочку. Плюсы такого механизма работы: 1) возможность поиска в словаре по словосочетаниям и без учета регистра (и не только по первому слову) 2) простота программы, легкость ее модификации и отладки 3) большая скорость работы (основные задержки приходятся на загрузку словарного файла в оперативную память с жесткого диска и при работе графического интерфейса)
Обратите внимание на размер оперативной памяти: если памяти достаточно (например, 64 Mb при использовании fvwm2), то повторные вызовы словаря намного быстрее первого, так как текст словаря остается в дисковом кэше и сразу становится доступными по мере надобности (исключается медленное копирование словаря с жесткого диска в оперативную память). Но работа при 32 Mb (при поиске без хеширования) практически невозможна (так как страницы со словарем быстро вытесняются на диск из оперативной памяти - при этом каждый новый запуск поиска включает чтение словаря с жесткого диска, что приводит к 1-2 с ожидания результата, но если начинает работать swap (при работе поиска), то время ожидания становится намного больше).
Сейчас movaTK и movaMTK использует хеширование при поиске слов сначала словарной статьи (опции -W и -B), это позволяет пользоваться словарем (с данными опциями) при меньших размерах ОЗУ. Словари отхешированы по первым двум буквам словарной статьи и хранятся в файле с названием словаря и добавлением к его названию слова ".hash". Цифра идущая за двухбуквенным сочетанием в строчке из файла хеша означает порядковый номер байта на котором кончается блок в котором все словарные статьи начинаются с данного двубуквенного сочетания. Если запросить поиск слова для которого нет хешированного двубуквенного начала, то включается обычный поиск (без использования хеша). К сожалению, маленький (а иначе индексирование не дает выигрыша) индексный файл получается при индексировании по ограниченному числу слов. Если же нужно иметь возможность поиска по всем словам словарной статьи (и, особенно, словосочетаниям), то хеширование не дает никакого выигрыша IMHO.
Основная работа по поиску строк и форматированию выполняется bash
скриптом - mova . В коммандной строке скрипту можно задать опции поиска, слово или последовательность слов для поиска и, в конце, полный путь к файлу словаря, в котором производится поиск. При этом, он будет искать слово сначала словарной строки (опция "-W"), первую часть слова сначала словарной строки (опция "-B"), последовательность слов внутри словарной строки (опция "-S", можно использовать как русско-английский словарь), последовательность символов (включая пробелы) внутри словарной строки (опция "-T"). Затем найденные строки пропускаются через sed фильтр, который добавляет к каждой словарной статье пустую строчку и форматирование по вариантам значения слова. В консоли лучше использовать аналогичные опции со строчными буквами (при этом подключается groff и less фильтры, а невидимые в koi8-r символы транскрипции перекодируются в видимые) см. screenshot
movaTK, см. screenshot
movaMTK использует другой способ вывода информации в окна (он удобнее, если нужно оставить на экране перевод ранее найденых слов, хотя работает медленнее). См. screenshot
movaTK и movaMTK раскрашивают в красный цвет транскрипцию и подставляют соответствующий фонт для символов между квадратными скобками. Голубым отмечаются английские слова, зеленым и наклонным шрифтом - служебные (грамматические еще выделяется жирным шрифтом). Слово или буквы поиска выделяются коричневым цветом. Часть словарной статьи до двух пробелов выделяется шрифтом FONT_FIND (этот же шрифт используется в желтой строчке ввода и для выделения слова в сером окне истории поиска).
Выйти из movaTK и movaMTK можно нажав "Esc"
Над и под скролбаром находятся квадратные кнопочки - с их помощью можно искать выделенное мышкой слово в уже выведенной словарной статье.
Напомню, как работают с этими оболочками. Слово или слова выделяются мышкой (при этом лишние пробелы не мешают). Затем из xterm или встроенной кнопкой (для fvwm2 отредактируйте файл .fvwm2rc в своей директории) запускается соответственный Tcl/Tk скрипт. Например, так
DestroyMenu "Utilities"
AddToMenu "Utilities@utilities-menu.xpm@^white^"
+ "Mueller7%mova_32x22.xpm%" Exec movaTK -W Mueller7GPL.koi&
+ "Mueller7 M%mova_32x32.xpm%" Exec movaMTK -W Mueller7GPL.koi& Оболочками можно пользоваться и без мышки. Для этого введите слово для перевода вручную в верхней (желтой) строке. При этом поиск с опцией "-W" запускается нажатием клавиши "Enter"; "-B" -
"Shift-Enter"; "-S" - "Ctrl-Enter"; а "-T" - "Alt-Enter".
Еще один важный управляющий скрипт: mova_sendTK. С его помощью можно послать выделенную мышкой строчку на перевод в первое открытое окно
movaTK для каждого словаря. Если открытого окна movaTK для
Mueller7GPL.koi нет, то будет запущена новая movaTK для этого словаря. Запускать mova_sendTK нужно с опциями для поиска, аналогичными для movaTK и mova. Если Вы хотите иметь возможность запускать поиск в словаре из любой программы на десктопе нажатием клавиш на клавиатуре, то добавьте в Ваш .fvwm2rc следующие строчки:
# Now some keyboard shortcuts.
#Keys for Mueller's dictionary
Key z A M Exec mova_sendTK -W &
Key В A M Exec mova_sendTK -W &
Key x A M Exec mova_sendTK -B &
Key Ъ A M Exec mova_sendTK -B &
Key a A M Exec mova_sendTK -S &
Key Т A M Exec mova_sendTK -S &
Key s A M Exec mova_sendTK -T &
Key Ш A M Exec mova_sendTK -T &
После перезапуска X-ов Вы получите возможность вызывать поиск выделенного мышкой слова в movaTK нажатием Alt-a (для поиска с опцией -S), Alt-s (для поиска с опцией -T), Alt-z
(для поиска с опцией -W), Alt-x (для поиска с опцией -B). Если клавиатура будет в koi8-r кодировке, то соответствующие клавиши будут работать также. Причем клавиши с Alt будут работать в любом месте десктопа и из окон большинства программ. Если запущенного movaTK нет, то нажатие этих клавиш запустит новый movaTK. Сечас mova_sendTK посылает указание переводить выделенное слово/слова извесным мне словарям (доступным в Интернете в формате "MOVA"). Список словарей для запуска находится в теле скрипта.
Иногда, wish не хочет посылать данные в уже открытую программу и говорит, что у него проблемы с секретностью. Попробуйте выполнить
xauth add :0 . `mcookie`
и затем добавьте в персональный .xserverrc
exec X :0 -auth ~/.Xauthority
и перезапустите X-ы
Словари, скрипты, настроечные файлы и описания размещаются согласно FHS (File Hierarchy Standard) - в /share/dict/, /share/mova/, /share/doc/mova/. При этом существует точка привязки всех используемых директорий (внутри скриптов это переменная DIR=/usr/local/). Точку привязки можно изменить в настроечных файлах - .movarc" или
.movarc_СЛОВАРЬ помещенных в домашнем каталоге или в DIR/share/mova/ или теле скрипта (при отсутствии настроечных файлов). Для инсталяции пакета скопируйте запакованный файл в корневую директорию "/" и выполните команды:
tar -xzf Mueller7GPL.tgz
tar -xzf script_mova.tgz
Для словарей с транскрипцией нужно добавить Sil-IPA шрифты в
XF86Config:
FontPath "/usr/X11R6/lib/fonts/sil_ipa/"
Родной сайт (http://www.sil.org/computing/fonts/encore-ipa.html) Sil-IPA шрифтов имеет еще и набор TrueType фонтов. Данные фонты распространяются под особой Free лицензией и для коммерческого использования нужно договариваться с авторами фонтов отдельно.
Все установки шрифтов и используемый по умолчанию словарь меняются в начале файла Tcl/Tk скриптов: в movaTK и movaMTK:
set FONT_FIND -*-*-bold-r-*-*-17-*-*-*-*-*-koi8-r
set FONT_TEXT -*-*-medium-r-*-*-17-*-*-*-*-*-koi8-r
set FONT_D -*-*-medium-o-*-*-17-*-*-*-*-*-koi8-r
set FONT_DG -*-*-bold-o-*-*-17-*-*-*-*-*-koi8-r
set FONT_IPA -*-silsophiaipa-*-r-*-17-*-*-*-*-*-*-*
set DIR /usr/local/
set DIR_TMP /tmp/
set DIC Mueller7GPL.koi
Можно также сделать отдельный файл настроек в домашнем каталоге с названием
".movarc", тогда будут считываться установки из этого файла. Если при запуске mova или movaTK/movaMTK в коммандной строке не указано название словаря, то по умолчанию будет запускаться поиск в словаре с именем
DIC. Пример соответствующего ".movarc",
-*-*-bold-r-*-*-20-*-*-*-*-*-*-koi8-r
-*-*-medium-r-*-*-20-*-*-*-*-*-koi8-r
-*-*-medium-o-*-*-20-*-*-*-*-*-koi8-r
-*-*-bold-o-*-*-21-*-*-*-*-*-koi8-r
-*-silsophiaipa-*-r-*-20-*-*-*-p-*-*-*
/usr/local/
/tmp/
Mueller7GPL.koi
Для индивидуальной настройки словарей, скажем для словарей европейских языков в ".movarc_СЛОВАРЬ" (где СЛОВАРЬ - имя файла словаря) нужно выставить подходящие фонты для FONT_FIND. Пример соответствующего
".movarc__СЛОВАРЬ",
-*-*-bold-r-*-*-20-*-*-*-*-*-*-1
-*-*-medium-r-*-*-20-*-*-*-*-*-koi8-r
-*-*-medium-o-*-*-20-*-*-*-*-*-koi8-r
-*-*-bold-o-*-*-21-*-*-*-*-*-koi8-r
-*-silsophiaipa-*-r-*-20-*-*-*-p-*-*-*
/usr/local/
/tmp/
И ".movarc" и ".movarc__СЛОВАРЬ" можно положить в директорию с настройками всего пакета - DIR/share/mova/. Они будут использоваться при отсутствии соответствующих файлов в домашней директории.
В самой верхней голубой строчке находятся кнопки:
Help - при нажатии выведится русский текст с краткой инструкцией по использованию оболочек.
Dictionary - выбор активного словаря. Открыть меню можно щелчком мышки или нажатием Alt-d
New Diary - при нажатии на эту клавишу слово отмеченное мышкой становится именем текущего Diary файла.
Add to Diary - добавляет содержимое окна вывода словарной статьи в конец текущего файла Diary.
Rewrite Diary - сохраняет текст в окне вывода словарной статьи в текущем файле Diary (по умолчанию это .mova) в домашнем каталоге пользователя. Предыдущее содержимое этого файла будет уничтожено.
Read Diary - можно выбрать Diary для вывода в окно. Открыть меню можно щелчком мышки или нажатием Alt-r
В директории DIR/share/mova/icons/ находятся иконки, специально сделанные для данного пакета, поместите их в директорию используемую windows manager для хранения иконок. mova_22x15.xpm; mova_32_22.xpm; mova_48x32 - для movaTK, а mova_22x22.xpm; mova_32_32.xpm; mova_48x48 - для
movaMTK. См. screenshot
Вы можете скачать последнию версию (версия 4.0) скриптов на www.chat.ru/~mueller_dic/script_mova.tgz или www.geocities.com/mueller_dic/script_mova.tgz.
20.7.99 Дмитрий Мищенко предупреждает пользователей FreeBSD, что команда fmt имеет в ней другие ключи (изменения должны быть внесены в mova: "fmt -s -w 45" нужно заменить на "fmt 45".
6.10.99 Игорь Готс предлагает возможность сохранения всех переведенных за день слов в специальном log файле. Для этого в файле mova замените:
&/g'|fmt -s -w 45;}
на
&/g'|fmt -s -w 45|tee -a /tmp/Mueller.`date|sed 's/[ ].*//g'`.log;}
Не забудьте вычищать старые логи каждую неделю :-)
Все вопросы, замечания и предложения присылайте Евгению Цымбалюку на mueller_dic@koi.chat.ru
#bn { DISPLAY: block } #bt { DISPLAY: block }
Начало работы
Редактор vi позволяет создавать новые файлы и редактировать существующие. Для запуска vi используйте команду vi сопровождаемую именем файла. Например для редактирования файла temporary наберите vi temporary и нажмите клавишу "Enter". Можно запустить vi без имени файла - в этом случае для сохранения результатов работы сообщите имя файла редактору позже.
Когда вы запускаете vi - на экране с левой стороны вы видите тильды (~). Так обозначаются пустые строки. В нижней части экрана отображается имя текущего файла и размер :
"filename" 21 lines, 385 characters Если это новый файл сообщение будет выглядеть следующим образом :
"newfile" [New file] При запуске vi без имени файла - нижняя часть экрана будет пустой. Если не отображается одно из этих сообщений - возможно у вас неверный тип терминала. Наберите :q и "Enter" для выхода из vi и установите поддерживаемый тип терминала. Если не знаете как - спросите совет у лаборанта.
Напечатать сначала третье, а затем второе поля каждой строки
SED: /[^ ]* [ ]*\([^ ]*\) [ ]*\([^ ]*\).*/s//\2\1/p (30.5 c.)
AWK: {PRINT $3 $2} (38.9 c.)
SED: /[^ ]* [ ]*\([^ ]*\) [ ]*\([^ ]*\).*/s//\2\1/p (30.5 c.)
AWK: {PRINT $3 $2} (38.9 c.)
Напечатать третье поле каждой строки
SED: /[^ ]* [ ]*[^ ]* [ ]*\([^ ]*\).*/s//\1/p (29.0 c.)
AWK: {PRINT $3} (33.3 c.)
SED: /[^ ]* [ ]*[^ ]* [ ]*\([^ ]*\).*/s//\1/p (29.0 c.)
AWK: {PRINT $3} (33.3 c.)
Напечатать все строки, содержащие "olga"
SED: /olga/p (11.6 c.)
AWK: /olga/ (25.6 c.)
Напечатать все строки, содержащие "olga", "mike" или "mal"
SED: /olga/p
/olga/d
/mike/p
/mike/d
/mal/p
/mal/d (15.8 c.)
AWK: /olga\bverb mike\everb mal/ (29.9 c.)
SED: /olga/p
/olga/d
/mike/p
/mike/d
/mal/p
/mal/d (15.8 c.)
AWK: /olga|mike|mal/ (29.9 c.)
Наращиваем мускулы Макросы и Shell
Надеюсь, мне удалось продемонстрировать, если и не все богатство штатных возможностей редактора NEdit, то - изрядную его долю. Однако величие программы в том, что штатными средствами его функциональность не исчерпывается. Поскольку может быть почти неограниченно наращена с помощью внутреннего языка макрокоманд - раз, и с помощью подключения скриптов командной оболочки - два.
Вкратце о возможности создания собственных макросов (путем написания их кода руками) я уже упоминал. Однако есть и другой способ, который для начала может оказаться более простым - протоколирование действий. Для этого требуется всего-навсего:
включить режим протоколирования (через меню Macro - Learn Keystrokes или через комбинацию Alt+K); произвести посредством клавиатуры (но не с помощью мыши!) все необходимые действия в той последовательности, в какой мы хотим их сохранить на будущее; завершить режим протоколирования (через меню Macro - Finish Learn или повторным нажатием комбинации клавиш Alt+K); в случае ошибки при наборе команд - прервать протоклирование (через меню Macro - Cansel Learn) и, включив протоклирование по новой, повторить требуемые действия уже без ошибок.
Запротоколированная последовательность действий будет фуркционировать в течение данного сеанса работы с NEdit. И может быть вызвана первый раз через меню Macro - Reply Keystrokes и, в дальнейшем, через Macro - Repeat. Однако при следующем запуске NEdit будет утрачена.
Чтобы этого не случилось, следует сохнанить ее в меню для потомства. Для этого, успешно завершив протоклирование данного макроса, отправляемся в меню Preferences, выбираем там пункт Default Settings, а в нем - опцию Customize Menu. Каковая, в свою очередь обнаруживает, как уже говорилось, пункт Macro Menu, вызывающий панель Macro Commands.
В списке доступных команд (в левой части панели) фиксируемся на пункте New. В поле Menu Entry задаем название команды и, при необходимости, название более высокого уровня для группы сходных команд, например, таким образом: Group commands>Command1
(без пробелов перед и после знака >). Здесь же можно приписать команду к какому-либо из доступных языковых режимов, например, Group commands>Command1@SGML/HTML
будет указывать, что данная команда активизируется только при выборе языкового режима SGML/HTML.
Затем заполняем поле Accelerator. Здесь за нашей командой можно закремить какую-либо клавишу (из числа, например, функциональных, или Windows-клавиш) или их комбинацию: например, сочетание клавиш Alt или Ctrl, возможно, в сочетании с Shift, с какой-либо буквой, желательно, имеющей мнемонический смысл.
Для этого достаточно просто зафиксировать зафиксировать курсор в поле Accelerator и нажать требуемую клавишу (например, F12) или их комбинацию (скажем, Ctrl+литера). Следует только внимательно следить, чтобы эта клавишная комбинация не использовалась для вызолва штатных функций NEdit: в этом случае приоритет в любом случае будет за последними, а, возможно, клавишная комбинация не будет вызывать ни старого, ни нового закремленного действия.
Вслед за этим можно заполнить поле Mnemonic, введя в него какую-либо букву из имени нашей команды (как оно указано в поле Menu Entry). При вызове меню буква эта будет подчеркнута и, теоретически, может использоваться для быстрого вызова команды (сочетанием ее с клавишей Alt). Однако на деле это работает далеко не всегда. Вернее, почти всегда не работает, поскольку болшинство букв латинского алфавита уже задействованы для штатных команд NEdit.
Наконец, последнее из предварительных действие - это включение, по потребности, переключателя Requires Selection. Он предназначен для команд, которые осуществимы только с предварительно выделенными фрагментами (типа компирования, вырезания и т.д.).
А вот теперь нажимаем экранную клавишу Paste Learn/Replay Macro (правой части панели). И текст макроса волшебным образом появляется в поле Macro Command to Execute. Где может быть любым образом отредатирован, дополнен, сокращен и т.д. После чего жмем клавишу OK, выходя их режима редактирования Macro Menu - и с удовольствием и пользой применяем новую функцию на практике. Если все работает нормально - сохранаяем текущюю ситуацию через Preferences - Save Defaults для увековечивания внесенных нами изменений.
Каковые, как уже говорилось, фиксируются в секции nedit.macroCommands:
файла . nedit из пользовательского каталога. Где также могут быть отредактированы непосредственно.
Таким образом можно насытить меню редактора NEdit командами для выполнения часто требуемых, но отстутствующих в штатном комплекте действий. Например, как будет показано ниже, для ввода тэгов HTML. Однако и этого может показаться недостаточным для полного счастья. Например, возникнет потребность в систематическом исполнении каких-либо внешних программ. Например, команд оболочки.
Конечно, на сей предмет можно прибегнуть к стандартному окну термиала - во-первых, к строке минитерминала (вызываемой через меню Shell - Execute Command, или клавишной комбинацией (Alt+X) - во-вторых, и к непосредственному вводу команд в поле редактирования NEdit с последующим их запуском (через меню Shell - Execute Command Line) - в третьих. Однако все это - не предел комфорта.
К тому же подчас необходимо, чтобы команда оболочки выполнялась в отношении редактируемого в данный момент в NEdit документа. Примером чего служит приведенная в прошлом разделе команда ispell для проверки орфографии. И тут нам на помощь приходит возможность редактирования меню Shell (через Preferences - Default Settings - Customize Menu - Shell Menu).
Выбрав соотвествующие пункты приведенной последовательности, вызываем панель Shell Commands и выбираем из списка доступных команд пункт New. Подобно тому, как это проделывалось для макросов, заполняем поля Menu Entry, то есть имени команды (также, возможно, иерархически построенного и привязанного к языковому режиму), Acceleretor (для закремления комбинаций клавиш) и Mnemonic (для выделения литеры быстрого вызова).
Затем определяемся c входными элементами команды в строке переключателей Command Input. Здесь можно предписать команде исполняться для выделенного фрагмента (selection), текущего окна (window), каждого элемента документа (either) или ни для чего (none). Объяснить смысл каждого переключателя в общем виде я несколько затрудняюсь, но на практике смысл их в отношении каждой конкретной команды обычно достаточно прозрачен.
Аналогично - и с выходными элементами команды. Каковые могут быть показаны в текущем или новом окне, а также в виде диалоговой панели.
Следующая ниже группа переключателей при установке в положение On предписывает:
замещать элемент ввода элементом вывода (Output replace input); сохранять текущий файл перед выполнением команды (Save file before executing command); перечитывать его же после выполнения таковой (Re-load file after execute command).
Определившись и с этим, можно непосредственно задавать команду вместе со всеми требуемыми параметрами и их значениями. Это делается в поле ввода команды (Shell Command to Execute), точно также, как в командной строке консоли или терминального окна.
Однако можно и набрать команду непосредственно в поле редактирования NEdit, после чего просто скопировать (с помощью мыши или клавишных комбинаций) ее в поле ввода команды. Преимущество последнего способа в том, что предварительно (с помощью меню Shell Execute Command Line) можно проверить работоспособность команды и, руководствуясь сообщениями об ошибках, ее отредактировать. Можно, разумеется, и просто скопировать успешно запускаемую команду и окна терминала...
Завершив создание новой команды, принимаем введенные изменений (через экранную кнопку Apply) или выходим из режима редактирования Shell через OK. А, выполнив проверку правильности созданной команды, сохраняем ситуацию (через Save Defaults) для использования в дальнейшем.
Наследие Emacs
Однако уже первое знакомство с TeXmacs убеждает в самостоятельном характере этой программы, который подчеркивается ее оригинальным (и весьма приятным) графическим интерфейсом. Более того, признаки влияния Emacs в ней отнюдь не бросается в глаза, если не считать заимствованной из этого редактора системы и некоторых рудиментов концепции буферов. То и другое, скажем так, терпимо, хотя и не представляется особенно полезным. Ведь потребность в визуальных редакторах обычно возникает у недавних Windows-мигрантов, а не у людей, досконально освоивших Emacs со всеми его клавиатурными комбинациями. Ну а список буферов в TeXmacs всё равно ограничивается окнами открытых документов, так что заимствованный из Emacs пункт меню можно было бы с успехом переименовать в и переместить из начала строки меню куда-нибудь поближе к ее концу.
Правда, есть у TeXmacs и еще одна черта, роднящая его не только с Emacs, но и с консольными редакторами вообще. В программе практически полностью отсутствуют диалоговые окна, так что в тех случаях, когда вызванная тем или иным способом команда требует задания каких-либо параметров, общение с пользователем происходит через строку состояния. Что, конечно, не очень удобно. Например, если пользователь выберет в меню команду , ему придется последовательно отвечать на вопросы о величине каждого из четырех полей, не забывая присовокуплять к введенной цифре название единицы измерения (например, cm, mm или in). Впрочем, похоже, что это не концептуальная особенность программы, а просто следствие нежелания автора пользоваться общераспространенными графическими библиотеками, типа gtk или motif.
Однако родство с Emacs станет по-настоящему очевидным, когда у нас возникнет желание заняться настройкой программы. Как выясняется, никаких интерактивных средств на сей случай не предусмотрено. Правда, в строке меню имеется пункт под названием , но он, во-первых, весьма беден по содержанию, и, во-вторых, установленные в нем параметры (можно, например, поменять язык интерфейса программы) действуют только на текущий сеанс. Что же, залезаем в программный каталог TeXmacs в надежде найти что-нибудь вроде конфигурационного файла (отметим, что имя этого каталога хранится в переменной $TEXMACS_PATH и соответствует /usr/share/TeXmacs, если программа устанавливалась из бинарного пакета; в противном случае придется поискать где-то в районе /usr/local/lib). На первый взгляд - абсолютно ничего. Так можно провести некоторое время в недоумении, пока не сообразишь присмотреться к каталогу $TEXMACS_PATH/progs, в котором обнаруживается целый куст инициализационных сценариев. Эти файлы имеют специфическое расширение .scm, но написаны они, по существу, на диалекте макроязыка Emacs lisp.
Правда, разобраться в содержимом папки progs будет несколько легче, чем в аналогичном хозяйстве для Emacs. Всё-таки сценариев в данном случае не так уж много, и они хорошо систематизированы. Кроме того, в TeXmacs нет ничего похожего на компилированные файлы .elc, назначение которых бывает затруднительно определить, если под рукой нет исходников. С другой стороны, расплатой за читабельность кода является довольно продолжительное время, уходящее на его обработку в процессе загрузки программы. Но так или иначе, а было бы недурно отыскать хоть какие-нибудь указания на методику обращения с этими файлами в документации к программе. Увы, автор программы, по-видимому, не предполагал, что потребность в информации такого рода может возникнуть у рядовых пользователей. Иначе чем объяснить то обстоятельство, что редактировать нам придется именно те файлы, которые находятся в программном каталоге TeXmacs? Ведь ничего похожего на файл ~/.emacs, который бы специально предназначался для задания пользовательских настроек, здесь не обнаруживается.
Настраиваем NEdit
Я уже говорил, большая часть настроек редактора NEdit сконцентрирована в пункте Preference главного меню. И даже кратко перечислил возможности натсройки текущей сесии. Однако нас больше интересует не сиюминутный результат настройки, но ее долгострочная перспектива. Для чего следует рассмотреть подпункт Preference - Default Settings. Содержание его близко подпунктам меню Preference и включает установки:
языкового режима (Language Modes); включения/выключения автоматических отступов (Auto Indent); режима переноса слов (Wrap); Tag Collisions; величины табуляции (Tabs); экранного шрифта (Text Fonts); настройки меню (Customize Menus); режима поиска (Searching); подсветки синтаксиса (Syntax Highlighting); переключателей вывода строки состояния (Statistics Line), строки поиска (Incremental Search Line) и нумерации строк (Show Line Numbers); резервного копирования (Make Backup Copy); Show Matching (...) Sort Open Prev. Menu; Popups Under Pointer; выдачи предупреждающих сообщений (Warning); начального размера окна при запуске NEdit (Initial Window Size).
Большинство из этих пунктов заслуживают того, чтобы задержать на них внимание. Чем мы и займемся, хотя и не в иной несколько последовательности. Но начнем по порядку, с языкового режима -
Настраиваем NEdit, или HTML-редактор своими руками
Алексей Федорчук
fedorchuk@geo.tv-sign.ru, http://linuxsaga.newmail.ru/
В предыдущей статье, посвященной UNIX-редактору NEdit*, автор попытался продемонстрировать если и не все богатство штатных возможностей NEdit, то buono parte (т. е. изрядную их долю). Однако подлинная ценность этого редактора состоит в том, что ее функциональность можно почти неограниченно наращивать с помощью внутреннего языка макрокоманд и с помощью подключения скриптов командной оболочки. Начнем с более простого способа, коим представляется создание макрокоманд.
*А. Федорчук. Текстовый редактор NEdit - на пути к идеалу. Byte/Россия, №12, декабрь 2000.
Настройка переменных редактора Emacs.
Другая частая причина редактирования файла .emacs заключается в изменении значений переменных. Процедуры Emacs используют в процессе работы переменные. Поэтому, изменяя значения встроенных переменных, можно влиять на поведение Emacs.
Некоторые переменные содержат числовые значения. Например, переменная next-screen-context-lines содержит количество строк данного экрана, остающихся при нажатии клавиш Page Up или Page Down. Если значение данной переменной - 2, то при нажатии одной из этих клавиш на экране останутся две строки от предыдущего экрана. Чтобы проверить значение данной переменной, введите C-h v, а затем имя переменной.
Значение переменных можно менять, если нажать M-x, а затем в командной строке ввести set-variable. Нажмите Enter, и Emacs запросит имя устанавливаемой переменной. После ввода имени Emacs запросит новое значение переменной.
Это - достаточно многоходовая комбинация, особенно если учесть имя переменной next-screen-context-lines. Если при каждом входе в Emacs, нужно устанавливать значение данной переменной равное 1, воспользуйтесь функцией Emacs LISP setq, чтобы автоматизировать данный процесс. Добавьте следующую строку в файл .emacs:
| (setq next-screen-context-lines 1) |
Не все переменные поддерживают числовые значения. Некоторые, такие как load-path, являются символьными переменными. load-path - список подкаталогов, куда обращается Emacs, когда необходимо загрузить файл, содержащий LISP-программу. Как будет показано в главе "Редактирование Документов SGML в редакторе Emacs и PSGML", при работе с PSGML нужно будет изменить значение переменной load-path.
Многие переменные Emacs являются Булевыми. Булева переменная (названная по имени английского математика Джорджа Була, жившего в 19-м веке) - подобна выключателю, который может иметь только два положения: вкл. или выкл. Emacs использует большое количество Булевых переменных, что дает возможность гибкой настройки его работы. Например, можно задать, чтобы при пошаговом поиске (C-s или C-r) Emacs осуществлял поиск либо с учетом, либо без учета регистра.
Управлять чувствительностью к регистру можно меняя значение переменной case-fold-search. Чтобы заставить Emacs игнорировать значение регистра при поиске, добавьте следующую строку в файл .emacs:
| (setq case-fold-search t) |
| (setq case-fold-search nil) |
Чтобы сохранить клавиатурные макросы в файле ".emacs" так, чтобы можно было использовать макрокоманду без дополнительного переопределения, используется команда insert-kbd-macro, которая добавляет эквивалент макроопределения, написанный на Emacs LISP, в текущий буфер. Рассмотрим пример.
Удобная макрокоманда для пользователей SGML быстрый ввод комментариев. Чтобы определить макрос и начать запись макрокоманды, сначала нажмите C-x (, а затем наберите
| <!-- --> |
Чтобы присвоить записанной макрокоманде имя, нажмите M-x и наберите в командной строке минибуфера name-last-kbd-macro. Допустим это имя - sgml-comment.
Затем, отредактируйте файл .emacs, или его эквивалент в операционной системе. Вставьте пустую строку, куда позднее будет вставлено макроопределение. Нажмите M-x, а затем в командной строке минибуфера введите команду insert-kbd-macro. Emacs запросит имя вставляемой макрокоманды, наберите sgml-comment. Появится следующее:
| (fset 'sgml-comment [?< ?! ?- ?- ? ? ?- ?- ?> left left left left]) |
| (global-set-key "^Co" 'sgml-comment) |
Настройка редактора Emacs.
Emacs обладает весьма гибким окружением, которое может быть легко приспособлено для выполнения конкретных задач. Например, Emacs позволяет запоминать последовательности комбинаций клавиш, чтобы не нажимать много раз подряд одни и те же кнопки. Emacs позволяет также изменять окружение через написание процедур на языке программирование Emacs LISP. Описанию данных возможностей посвящена эта глава.