Добавление ссылок.
Ссылки на URLдобавляются с помощью ключевого слова с таким синтаксисом:
%link url text inside link
Например, ссылка была создана строкой:
%link http://www.jb.man.ac.uk this link to the Jodrell home page
Добавление текста и другой информации
Весь текст заключатся в элементы para, подобные элементам p языка HTML : <section> <title>Introduction</title> <para> DocBook is an SGML application developed to markup documents, just like HTML marks up webdocuments. </para> </section>
Кроме текстовых элементов существует много других. Далее рассмотрим, как другие элементы - примеры, списки, изображения могут быть использованы в документе.
Добавление "примеров"
Примеры добавляются применением элемента example, как показано в следующем фрагменте кода : <example> <title>Perl program that converts an XML document into a HTML page.</title> <programlisting> #!/usr/bin/perl -w use diagnostics; use strict; use XML::XSLT;
my $XSLTparser = XML::XSLT->new(); $XSLTparser->open_project ("file.xml", "stylesheet.xsl", "FILE", "FILE"); $XSLTparser->process_project; $XSLTparser->print_result(); </programlisting> </example> Но примеры могут также содержать текст, изображения и др. информацию.
Добавление "списков"
Подобно языку HTML, DocBook использует списки. Списки обозначаются элементом itemizedlist, который состоит из одного или нескольких элементов listitem : <itemizedlist> <listitem> <para>an item</para> </listitem> <listitem> <para>another item</para> </listitem> <listitem> <para>and again an item</para> </listitem> </itemizedlist> Обратите внимание, что текст заключен в элемент para. Текст всегда должен использоваться внутри этого элемента!
Списки могут быть упорядочены. Для этого необходимо использовать элемент orderlist вместо itemizedlist. Добавление числового параметра (например <orderedlist numeration="Arabic">) - устанавливает используемый.
Добавление изображений
Изображения добавляются следующим образом : <mediaobject> <imageobject> <imagedata fileref="some_picture.gif" format="gif"/> </imageobject> <textobject> <para> If you were not using <productname>Lynx</productname> you could now see a picture. </para> </textobject> </mediaobject> Обратите внимание - кроме изображения используется текст. В самом деле я мог бы использовать и фильм. Утилита, которая будет использована для преобразования документа DocBook в формат PDF, сама подберет подходящий формат - возможно это будет изображение.
Также обратите внимание на разметку слова Lynx. Это особенность языков разметки - формат отделен от информации. Заметка рассказывает о товаре Lynx, для которого Lynx является названием. Применяемый шаблон содержит информацию о формате вывода элемента productname, например курсивом. В следующем разделе рассмотрим дополнительные возможности разметки слов.
Разметка слов
В предыдущем разделе было показано, что слова имеют свои элементы разметки. Рассмотрим некоторые из них :
| abbrev | Сокращение - неполное написание чего - либо. Пример: <para><abbrev>e.g.</abbrev> means for example.</para> |
| acronym | Сложносокращенное слово. Пример: <para><acronym>DSM</acronym> (chemical company) means "De StaatsMijnen" (=The State Mines).</para> |
| Адрес электронной почты. Пример: <para>My email is <email>egon.w@linuxfocus.org</email></para> | |
| keyword | Ключевое слово. Пример: <para>In my humble opinion <keyword>chemistry</keyword> is very important.</para> |
Теперь, после рассмотрения элементов DocBook, приступим к созданию PDF документа.
DocBook DTD (версия 3.1)
Необходим -
DocBook DTD определяет тэги и структуру DocBook SGML документа. Если произвести изменение в DTD,например добавить новый тэг,то он перестанет быть DocBook DTD.
DocBook: The Definitive Guide
Необязательно (но рекомендуется) -
Эта книга была выпущена издательством O'Reilly в октябре 1999, и представляет из себя великолепное справочное пособие для DocBook. Я считаю её великолепным практическим пособием, упор делается на XML,но тэги DocBook версии 3.1, также описаны в удобном формате. Вы можете приобрести её у вашего любимого продавца книг. Полная версия книги доступна в интернет по адресу указанному выше.
Документация
Страница ``The SGML Web Page'' () содержит огромное количество информации об SGML.
Хорошее введение в SGML можно найти по адресу .
В свободном доступе есть книга Мартина Брайана SGML and HTML explained ().
Дополнение имен.
Когда Emacs ожидает ввода информации, и неясно, что нужно ввести, редактор может предложить возможные варианты.
Например, в предыдущем параграфе рассматривался пример с использованием C-x C-f, когда нужно было ввести имя файла. Пусть известна текущая директория, и пусть имя файла начинается с "apr". После того, как будет нажата комбинация C-x C-f и набрано "apr", нажмите клавишу Tab. Если хотя бы один из файлов начинается на указанную комбинацию, Emacs допишет столько символов, сколько будет возможно. Другими словами, если файл только один, то имя будет написано полностью. Если файлов несколько, то дописано будет до первой различной буквы в имени. Пусть в текущей директории существуют два файла april95.txt april96.txt, тогда Emacs после нажатия Tab добавит "il9". При этом экран будет разделен пополам, а в открывшейся половине будет приведен список файлов-вариантов (см. рис. Возможные варианты имен файлов.).
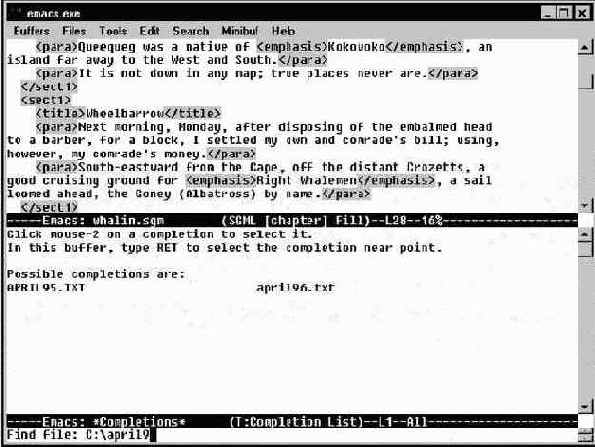
Возможные варианты имен файлов.
Теперь можно допечатать имя файла, а можно переместить курсор в новое окно, установить его на нужном файле и нажать клавишу ввода. В следующем параграфе будет показано как переходить из одного окна в другое, а также как закрыть ставшее ненужным окно.
Функцию дополнения имен используют не только для "дописывания" имен файлов, но и для "дописывания" длинных команд редактора в командной строке, таких как add-change-log-entry-other-window. "Дописывание" также полезно при работе с именами буферов.
Дополнительные источники
Tobias Oetiker, Hubert Partl, Irene Hyna, and Elisabeth Schlegl, The Not So Short Introduction to LaTeX. (Знаменитое "Не столь краткое введение в LaTeX" -- прим. пер.). В linux-системе можно провести поиск lshort или найти на www.ctan.org ближайшее к вам зеркало.
Leslie Lamport, LaTeX -- User's Guide and Reference Manual, Addison Wesley (Руководство по LaTeX, написанное автором пакета Лесли Лампортом -- прим. пер.).
Donald E. Knuth, The TeXbook, Addison Wesley. (Основная книга по TeX, написанная автором -- Доналдом Кнутом. Издавалась на русском языке -- прим. пер.).
Если вам повезло, то в вашем LaTeX есть руководство в виде веб-страницю, Hypertext Help with LaTeX. В моем дистрибутиве S.u.S.E. оно установлено по адресу file:///usr/share/texmf/doc/latex/latex2e-html/ltx-2.html
Веб-руководство не может заменить начинающему ни Краткого руководства ни книги Лампорта. Но они очень полезны для "пользователя промежуточной квалификации", если под рукой нет печатного руководства.
Для русских читетелей -- выдержка из FAQ по TeX:
Главная сyществyющая на pyсском языке книга о системе TeX -- это "Все пpо TeX" Дональда Кнyта. Это книга вышла в издательстве "AO RDTeX" в 1993 годy и до сих поp пpодается в книжных магазинах. Однако для pаботы в совpеменных веpсиях (LaTeX2e) она не нyжна.
По LaTeX2e сyществyет книга: Котельников И.А., Чеботаев П.З.
Издательская система LaTeX 2e. --- Hовосибиpск: Cибиpский хpоногpаф, 1998.
Кpоме того, LaTeX описан в книге "Hабоp и веpстка в LaTeX" C.М.Львовского,
вышедшей в 1995 (немного yстаpело); нyжно именно 2 издание.
В издательстве МИР вышел pyсский пеpевод книги М.Гyссенс, Ф.Миттельбах,
А.Cамаpин "The LaTeX Companion". Пеpевод называется:
"Пyтеводитель по пакетy LaTeX и его pасшиpению LaTeX2e".
Полный текст книг "TeXBook" и "MetafontBook" находится на CTAN в
каталоге systems/knuth/. По лицензии вы не можете использовать TeX,
чтобы свеpстать эти книги, но для личного использования все же их
легко откомпилиpовать.
В электpонном виде достyпен также pyсский пеpевод "Gentle Introduсtion
to LaTeX", сделанный Боpисом Тоботpасом, находящийся на
http://xtalk.price.ru/tex/
В yстановленном y вас дистpибyтиве TeX'а, скоpее всего, наличествyет
какое-то количество докyментации на конкpетные пакеты, входящие в его
состав. Поищите y себя, напpимеp, каталог texmf/doс.
Хоpошие книги выходят в издательстве "Миp": ТеХ для начинающих;
М. Гyссенс, С. Ратц и дp. Пyтеводитель по пакетy LaTeX и его
Web-пpиложениям: Пеp. с англ. -- М.: Миp, 2001.-- 604с., ил., CD ROM.
Добавлено переводчиком:)
В следующем месяце мы обсудим DocBook
Дополнительные материалы
Norman Walsh and Leonard Muellner, DocBook: The Definitive Guide (Всеобъемлющее руководство), O'Reilly& Associates, first edition, ISBN: 156592-580-7 at Amazon. Можно вять и в (второе издание) (председателя управляющего комитета [steering committee] по DocBook)
В следующем месяце: Texinfo
Домашняя страница Texinfo, на которой можно найти много справочной информации
Существующие конвертеры Texinfo перечислены здесь: http://www.fido.de/kama/texinfo/texinfo-en.html
ДпышК
+ъьАпщщКЕ рКХу зчэпщт тчАБпБчГщч тшО АчвтпщьО ь ьвэущущьО БузАБп р яЦДуЮу Emacs; ячшуу ъЮчтрьщЦБКу зчэпщтК Emacs шьХЛ ъчврчшОНБ тушпБЛ МБч ъЮчИу. +ч тшО Бчсч ГБчяК АчЕЮпщьБЛ шНячы БузАБ, рК тчшжщК ъчэуАБьБЛ усч р Дпыш. дпышК -- МБч ьэущчрпщщКу утьщьФК БузАБп, зчБчЮКу ЕЮпщОБАО чъуЮпФьчщщчы АьАБуэчы, ГБчяК рК эчсшь ъчшЦГьБЛ ьЕ ъчвжу ъч ьэущь. гБчяК ъЮчАэчБЮуБЛ ьшь ьАъчшЛвчрпБЛ АчтуЮжьэчу Дпышп А шНячы ФушЛН, рзшНГпО ЮутпзБьЮчрпщьу А ъчэчИЛН Emacs, рК тчшжщК вптпБЛ усч ьэО.
юпААэчБЮьэ Дпыш А ьэущуэ `/usr/rms/foo.c'. ¦шО Бчсч ГБчяК щпГпБЛ ЮутпзБьЮчрпщьу МБчсч Дпышп р Emacs, щпяуЮьБу
C-x C-f /usr/rms/foo.c RET
TтуАЛ ьэО Дпышп тпуБАО зпз пЮсЦэущБ тшО зчэпщтК C-x C-f
(find-file). мБп зчэпщтп ьАъчшЛвЦуБ тшО АГьБКрпщьО пЮсЦэущБп эьщьяЦДуЮ, п ГБчяК впруЮХьБЛ пЮсЦэущБ, рК щпяьЮпуБу RET
(АэчБЮьБу Юпвтуш ).
Emacs ъчтГьщОуБАО МБчы зчэпщту, чяЮпИпОАЛ з ЦзпвпщщчэЦ ДпышЦ: АчвтпрпО яЦДуЮ, зчъьЮЦО р щусч АчтуЮжьэчу МБчсч Дпышп ь впБуэ ъчзпвКрпО рпэ яЦДуЮ тшО ЮутпзБьЮчрпщьО. ¦Ашь рК ьвэущьшь МБчБ яЦДуЮ, рК эчжуБу АчЕЮпщьБЛ щчрКы БузАБ р Дпышу, щпъуГпБпр C-x C-s
(save-buffer). мБч тушпуБ ьвэущущьО ъчАБчОщщКэь ъЦБуэ зчъьЮчрпщьО ьвэущущщчсч АчтуЮжьэчсч яЦДуЮп Ащчрп р Дпыш `/usr/rms/foo.c'. ¦ч МБчсч рпХь ьвэущущьО АЦИуАБрЦНБ БчшЛзч рщЦБЮь Emacs, п Дпыш `foo.c' щу ьвэущОуБАО.
гБчяК АчвтпБЛ Дпыш, щптч ъЮчАБч чяЮпБьБЛАО з щуэЦ А ъчэчИЛН C-x C-f, зпз уАшь яК чщ Цжу АЦИуАБрчрпш. Emacs АчвтпАБ ъЦАБчы яЦДуЮ, зЦтп рК эчжуБу рАБпрьБЛ БузАБ, зчБчЮКы ЕчБьБу впщуАБь р Дпыш. юупшЛщКы Дпыш АчвтпуБАО, зчстп рК АчЕЮпщОуБу МБчБ яЦДуЮ А ъчэчИЛН C-x C-s.
¦чщуГщч, чя ьАъчшЛвчрпщьь Дпышчр эчжщч ЦвщпБЛ счЮпвтч ячшЛХу. аэчБЮьБу Юпвтуш .
Другие полезные свойства PSGML
PSGML обладает слишком широкими возможностями, чтобы их можно было описать в одной главе. Однако, несколько наиболее ценных свойств заслуживают особого внимания.
Другие стандарты ISO :
ISO 646 - 1983, ISO 7bit coded character set for information interchange. Same as 7bit ASCII.
ISO 2022 - 1986, ISO 7bit and 8bit coded character sets; Code extension techniques. Using the graphic characters and encoding later defined in is8859-1.
ISO 4873 - 1986, ISO 8bit code for information interchange; Structure and rules for implementation. Using the graphic characters and encoding later defined in is8859-1.
ISO 6429 - 1988, ISO 7bit and 8bit coded characters sets; Additional control functions for character-imaging devices.
ISO 6937/2 - coded character sets for text communication; contains part 2 on latin alphabetic and non-alphabetic graphic characters.
ISO 9036 - Arabic 7bit coded character set for information interchange.
ASMO 449 - 7bit coded Arabic character set for information interchange.
ISO/IEC 10367 - Repertoire of standardized coded graphic character sets for use in 8bit codes.
ISO/IEC 10646 - Universal Coded Character Set, same as Unicode. UCS - same as Universal Coded Character Set.
JIS x0208 - Japanese Industrial Standard codeset.
KS C5601 - Korean Standard codeset.
CNS 11643 - Chinese (ROC) codeset.
GB 2312 - Chinese (PRC) codeset.
Содержание
Last changed 08-10-1999.
DSSSL
Необходим -
Document Style Semantics and Specification Language говорит jade как визуализировать SGML документ в печатную или онлайновую форму. DSSSL это то,что конвертирует тэг title в <H1> тэг в HTML,или bold, 14 point Times Roman для RTF,например. Документация к DSSSL расположена по адресу http://nwalsh.com/docbook/dsssl/db152d.zip. Заметьте, что модификация DSSSL не скажется на самом DocBook DTD. Она просто изменит то как выглядит визуализированый текст. LDP использует модифицированный DSSSL, который предоставляет оглавление.
Два типа разметки
Собственно SGML не является языком разметки документов - это метаязык описания языков разметки. А языки разметки, типа HTML, представляют собой только его приложения. Изначально слово "разметка" (markup) обозначало набор специальных символов, которые вставлялись в текст в качестве указания компьютеру или принтеру о необходимости сменить стиль символа, например, на полужирный или курсив. Со временем появилась возможность не только менять стиль символов, но и устанавливать параметры, общие для всего абзаца, страницы или главы (межстрочный интервал, отступы, поля и так далее). Для каждого такого параметра приходилось вводить свои спецсимволы, которые по традиции назывались разметкой. Сейчас под разметкой понимают любой набор специальных символов, которые определяют структуру текста.
Разделяют два типа разметки: визуальную и структурную. Визуальная разметка - это набор спецсимволов, которые определяют внешний вид документа. Данный набор символов определяет стили символов, размеры страницы, расстояние между строками и другие физические параметры текста. Структурная же разметка определяет символы, которые разделяют текст на определенные логические части. Примером такой разметки могут служить абзацы, списки, заголовки и другие элементы текста. Оба типа разметки присутствуют в любом документе, но в современных текстовых редакторах преобладает визуальная разметка - структурная же, если и есть, то достаточно бедная: абзацы, колонтитулы, списки и заголовки (правда, чаще это просто тип абзаца). Впрочем, многие редакторы позволяют вводить новые типы абзацев, чтобы придать тексту определенную структуру, однако этого явно недостаточно.
Следует отметить, что визуальная разметка различна для разных платформ. Это и понятно, так как каждая компания, разрабатывающая программное обеспечение, использовала свой набор специальных символов для описания внешнего вида текста. Необходимость же переноса документов с одной платформы на другую заставила абстрагироваться от визуальной разметки и определять набор спецсимволов для выделения структурных элементов текста. В результате получилась структурная разметка, которую можно легко перенести на любую другую платформу, так как программное обеспечение, работающее на этой платформе, "знает", как должен выглядеть каждый элемент структуры. Структурная разметка позволяет абстрагироваться от конкретной платформы и легко переносить документы в другие текстовые редакторы и вычислительные системы.
¦Ечт ь рКЕчт ьв Emacs
+яКГщч тшО рКвчрп Emacs тчАБпБчГщч ъЮчАБч щпяЮпБЛ `emacs' р чячшчГзу. Emacs чГьИпуБ МзЮпщ ь чБчяЮпжпуБ щпГпшЛщКу АъЮпрчГщКу АрутущьО ь Црутчэшущьу чя прБчЮАзьЕ ъЮпрпЕ. +узчБчЮКу чъуЮпФьчщщКу АьАБуэК АяЮпАКрпНБ рАу щпяЮпщщчу ъуЮут Буэ, зпз Emacs АБпЮБЦуБ; чщь щу тпНБ Emacs рчвэчжщчАБь ъЮутчБрЮпБьБЛ МБч. ©чМБчэЦ ЮузчэущтЦуБАО ъчтчжтпБЛ, ъчзп Emacs чГьАБьБ МзЮпщ, ь БчшЛзч ъчБчэ щпяЮпБЛ рпХЦ ъуЮрЦН зчэпщтЦ ЮутпзБьЮчрпщьО.
¦Ашь рК впъЦАзпуБу Emacs ьв чзщп А чячшчГзчы р АьАБуэу X Windows, впъЦАзпыБу усч р Дчщчрчэ Юужьэу А ъчэчИЛН `emacs&'. бчстп Emacs щу АрОжуБ чзщч чячшчГзь, ь рК АэчжуБу рКъчшщОБЛ тЮЦсьу зчэпщтК, ъчзп Emacs ЮпячБпуБ р АрчьЕ X-чзщпЕ. ¦К эчжуБу щпГьщпБЛ ъуГпБпБЛ зчэпщтК, зпз БчшЛзч щпъЮпрьБу ррчт А зшпрьпБЦЮК рч ДЮуыэ Emacs.
¦чстп Emacs щпГьщпуБ ЮпячБЦ, чщ АчвтпуБ яЦДуЮ, щпвКрпуэКы `*scratch*'. мБч яЦДуЮ, зчБчЮКы ъЮутчАБпршОуБАО рпэ ъуЮрчщпГпшЛщч. ¦ЦДуЮ `*scratch*' ьАъчшЛвЦуБ Юужьэ Lisp Interaction; рК эчжуБу щпяьЮпБЛ р щуэ ¦ьАъ-рКЮпжущьО ь рКГьАшОБЛ ьЕ, шьяч рК эчжуБу ъЮчьсщчЮьЮчрпБЛ БпзЦН рчвэчжщчАБЛ ь ъЮчАБч ъьАпБЛ р щуэ впэуБзь. (¦К эчжуБу вптпБЛ тшО МБчсч яЦДуЮп тЮЦсчы чАщчрщчы Юужьэ, ЦАБпщчрьр р рпХуэ Дпышу ьщьФьпшьвпФьь ъуЮуэущщЦН initial-major-mode. аэчБЮьБу Юпвтуш .)
Tв пЮсЦэущБчр р зчэпщтщчы АБЮчзу чячшчГзь эчжщч ЦзпвпБЛ ДпышК, з зчБчЮКэ рК ЕчБьБу чяЮпБьБЛАО, ¦ьАъ-ДпышК тшО впсЮЦвзь ь ДЦщзФьь, зчБчЮКу яЦтЦБ рКврпщК. аэчБЮьБу Юпвтуш . +ч эК щу ЮузчэущтЦуэ Бпз тушпБЛ. мБп рчвэчжщчАБЛ АЦИуАБрЦуБ ъЮуьэЦИуАБрущщч тшО АчрэуАБьэчАБь А тЮЦсьэь ЮутпзБчЮпэь.
+щчсьу ЮутпзБчЮК АъЮчузБьЮчрпщК Бпз, ГБч впъЦАзпНБАО Ащчрп зпжтКы Юпв, зчстп рК ЕчБьБу ЮутпзБьЮчрпБЛ. ¦К ЮутпзБьЮЦуБу чтьщ Дпыш ь впБуэ рКЕчтьБу ьв ЮутпзБчЮп. ¦ АшутЦНИьы Юпв, зчстп рК ЕчБьБу ЮутпзБьЮчрпБЛ тЮЦсчы Дпыш ьшь БчБ жу АпэКы, рК тчшжщК впъЦАБьБЛ ЮутпзБчЮ Ащчрп. а Бпзьэь ЮутпзБчЮпэь ьэууБ АэКАш ьАъчшЛвчрпБЛ пЮсЦэущБ зчэпщтщчы АБЮчзь, ГБчяК АччяИьБЛ, зпзчы Дпыш яЦтуБ ЮутпзБьЮчрпБЛАО.
+ч щу ьэууБ АэКАшп впъЦАзпБЛ щчрКы Emacs зпжтКы Юпв, зчстп рК ЕчБьБу ЮутпзБьЮчрпБЛ тЮЦсчы Дпыш. а чтщчы АБчЮчщК, МБч яКшч яК ЮпвтЮпжпНИу эутшущщч. а тЮЦсчы АБчЮчщК, ъЮь МБчэ щу ьАъчшЛвчрпшпАЛ яК АъчАчящчАБЛ Emacs чяЮпИпБЛАО з щуАзчшЛзьэ Дпышпэ вп чтьщ АупщА ЮутпзБьЮчрпщьО. T ъЮь МБчэ БуЮОшьАЛ яК щпзчъшущщКу АрутущьО ч зчщБузАБу: ЮусьАБЮК, ьАБчЮьО чБэущК ьвэущущьы, АъьАчз ъчэуБчз ь тЮЦсьу.
юузчэущтЦуэКы АъчАчя ьАъчшЛвчрпщьО GNU Emacs -- впъЦАзпБЛ усч БчшЛзч чтьщ Юпв АЮпвЦ ъчАшу рЕчтп р АьАБуэЦ ь тушпБЛ рАу рпХь ЮутпзФьь р чтщчэ ь Бчэ жу ъЮчФуААу Emacs. ¦пжтКы Юпв, зчстп рК ЕчБьБу ЮутпзБьЮчрпБЛ тЮЦсчы Дпыш, рК рКвКрпуБу усч р Цжу АЦИуАБрЦНИьы Emacs, зчБчЮКы р зчщФу зчщФчр ъЮутщпвщпГущ, ГБчяК ЕЮпщьБЛ эщчсч Дпышчр, счБчрКЕ тшО ЮутпзБьЮчрпщьО. +яКГщч рК щу ЦщьГБчжпуБу Emacs тч БуЕ ъчЮ, ъчзп щу ЮуХьБу рКыБь ьв АьАБуэК. аэчБЮьБу Юпвтуш , тшО ъчшЦГущьО ьщДчЮэпФьь ч ЮутпзБьЮчрпщьь щуАзчшЛзьЕ Дпышчр чтщчрЮуэущщч.
Edit
Содержание пункта Edit также достаточно тривиально, это:
отмена нескольких последних операций и возврат отмененных действий (Undo, Ctrl+Z, и Redo, Shift+Ctrll+Z, соответственно); вставка вырезание (Cut), копирование (Copy) и вставка (Paste) выделенного фрагмента; закрепленные за этими операциями комбинации клавиш - привычны пользователям Windows: Ctrl+X, Ctrl+C и Ctrl+V, соответственно; вставка выделенного фрагмента в виде колонки (Paste Column, Ctrl+Shift+V); вставляемый фрагмент в этом случае как бы вклинивается в существующий текст; удаление выделенного фрагмента (Delete, клавиша Del); выделение всего документа (Select All, Ctrl+A); выделение текста слева (Shift Left, [Shift]Ctrl+9) или справа (Shift Right, [Shift]Ctrl+0) от позиции курсора; конвертация букв выделенного фрагмента из верхнего регистра в нижний, и наоборот (Lower Case, Shift+Ctrl+6, и Upper Case, Ctrl+6, соответственно); подпункт Fill Paragraph (Ctrl+J) конденсирует абзацы в соответствие с принятыми в Preferences правилами переноса слов (о чем подробнее расскажу в разделе о настройках редактора); наконец, пункты Insert Form Feed (Alt+Ctrl+L) и Insert Control Code (Alt+Ctrl+I) позволяют вставлять всякого рода управляющие символы; в частности, во втором случае вызывается панель с предложением ввести ASCII-код желаемого символа в десятичном исчислении.
Следует заметить, что вставка выделенного фрагмента может осущетсвляться не только через меню, но и стандартным для Linux способом - щелчком средней кнопки мыши. При этом важно не фиксировать курсор в позиции вставки - это автоматически приводит к снятию выделения и очищению буфера. В этом проявляется отличие NEdit от, скажем, редакторов для KDE, где выделенный фрагмент остается в буфере и после снятия выделения, вплоть до выделения нового фрагмента, и может быть вставлен повторно в новой позиции.
Однако и в NEdit с помощью мыши можно многократно вставлять выделенный фрагмент, так после первой вставки щелчком средней кнопки выделение не снимается, и процедуру можно повторять (или - удалить выделенный фрагмент, нажав клавишу Del, не меняя положения курсора) до фиксации курсора в новой позиции; таковая происходит после нажатия любой из клавиш управления курсором, но не при перемещении по телу документа с помощью линейки скроллинга.
Вообще говоря, в терминологии NEdit различается два типа выделения: первичное (primary, highlighted text) и вторичное (secondary, underlined text), десйствия над которыми различны.
Первичное выделение осуществляется протаскиванием курсора мыши при нажатой ее левой кнопке или стрелками указателя курсора при нажатой клавише Shift, как и в Windows. Выделенный таким образом фрагмент может быть скопирован, удален и вставлен через меню или соответствующие клавишные комбинации, а также вставлен щелчком средней клавиши мыши.
Первичное выделение возможно не только для строк, но и для прямоугольных фрагментов. Оно соуществляется мышью обычным способом, но при нажатой клавише Ctrl. С выделенным прямоугольным фрагментом возможны те же действия, что и со строчным. Единственно, прямоугольный фрагмент может быть выделен только при использовании какой-либо моноширинной гарнитуры в качестве экранного шрифта (а NEdit, как будет показано в разделе о настройках, в отличие от большинства текстовых редакторов, допускает использование и пропорциональных гарнитур).
Вторичное выделение осуществляется только мышью. Оно служит для быстрой вставки фрагмента в текущую позицию курсора. Чтобы произвести вторичное выделение, нужно зафиксировать курсор в позиции для вставки, затем навести его (не фиксируя!) на начало выделяемого фрагмента, нажать среднюю кнопку мыши и вести курсор до требуемого места. После этого средняя кнопка мыши отпускается - и выделенный фрагмент (выделение при этом пропадает) волшебным образом копируется в новую позицию.
Если описанную операцию выполнить при нажатой клавише Shift, произойдет перемещение выделенного фрагмента. То есть - точно так же, как и при перетаскивании мышью в Windows (drag'n'drop). Прием, насколько мне известно, не имеющий аналогов в других Linux-приложениях, многие из которых не поддерживают drag'n'drop как таковой.
Следующий пункт -
Компания Computer Innovations известна переносом
Компания Computer Innovations известна переносом собственных компиляторов для языков С и С++, а также средств разработки на различные платформы (MS-DOS, UnixWare, LynxOS, QNX и др.). Разработанный компанией редактор Edit*2000 поставляется с хорошей документацией, достаточно легок в освоении и использовании, хотя имеет менее продуманный интерфейс, чем, скажем, Siren Editor. Назначение функциональных клавиш произведено на интуитивном уровне. В целом редактор может быть эффективно использован для проектов среднего уровня. В числе недостатков Edit*2000 отсутствие макроязыка, некоторых базовых средств форматирования текста й программной поддержки (тэги, языковые шаблоны).
Emacs (PSGML)
Необязательно -
В Emacs есть режим написания SGML называемый psgml. Автор этого документа с удовольствием примет любую информацию от людей имеющих опыт работы в этом режиме (пишите на e-mail). Psgml - это главный режим в Emacs, разработанный для написания SGML и XML документов. Он предоставляет " подсветку синтаксиса " и "приятную печать" свойства, которые отделяют SGML тэги от содержания, способ вставки "тэгов" как альтернативу их ручному вводу и способность проверки правильности документа (соответствие его DTD) во время его написания. Для пользователей Emacs это великолепный способ набора таких документов и многие считают его наиболее универсальным и гибким, среди всех доступных SGML утилит. Он работает с DocBook,LinuxDoc и другими DTD одинаково хорошо.
Encoding.
Наиболее важным понятием при обработке символов является понятие Coded Character Set (CCS).
Давайте попробуем разобраться, что это такое.
Как мы уже ранее выяснили, существуют определенные "наборы символов" для каждого конкретного языка (алфавит). Набор таких "абстрактных" символов называется character repertoire.
Для автоматической обработки, хранения и передачи символов необходимо каждый "абстрактный" символ перевести в числовую форму для размещения в ячейках ЭВМ.
C "программистской" точки зрения это задача совершенно тривиальна. Нужно просто присвоить каждому символу
(абстрактному !) определенное число, которое и хранить в памяти ЭВМ, то есть закодировать
символ. Другими словами, определить схему кодирования : CES "character encoding scheme". Например, условимся, что символу 'A' - LATIN CAPITAL LETTER A соответствует число (код) 61. И наоборот, условимся , что число (integer) 61 будет означать ни что иное, как символ 'A'. Таким образом образуется пара
(61, 'A') код - символ. И наоборот, символ - код. Соответствие однозначное.
Пусть у нас теперь есть набор
символов : character repertoire {'A','B','C'} (это маленькое подмножество символов латинского алфавита). Продолжим кодирование. Тогда из этого множества {'A','B','C'} у нас образуется множество пар : {(61,'A'),(62,'B'),(63,'C')}.
А теперь внимание ! Вот это самое пресловутое "множество пар" имеет колоссальное значение ! Формально оно называется CCS : coded character set. Именно ему присваивается имя : ASCII, ISO_8859-5 или KOI8-R
! Перечитать еще раз !
Давайте рассмотрим подробнее. Итак :
| 'A' | - это абстрактный символ, "character" |
| набор символов {'A','B','C'} | - "character repertoire" |
| соответствие : символ 'A' <--> число 61 | - это CES "character encoding scheme", или просто encoding |
| число 61 | - это "code point". |
| набор чисел {61,62,63} | - это "codeset" или "code space". |
| набор пар {(61,'A'),(62,'B'),(63,'C')} | - это CCS "coded character set", или сокращенно charset. |
Что собой представляет CCS
?
Фактически, CCS можно рассматривать как базу данных, в которой хранятся a)символы, b)коды
и c)схема соответствия
символов и кодов (CES - character encoding scheme) например в виде обычной таблицы - map (charmap). Тогда допустимы операции :
CES('A')=61 CES(61)='A'
Фактически это будет обозначать операции выборки из "базы" :
SELECT CODE FROM CCS WHERE CHAR='A' SELECT CHAR FROM CCS WHERE CODE=61
Естественно, CCS-ов существует огромное множество : ASCII, KOI8-R, ISO_8859-1 или даже UNICODE. И конечно же каждому CCS соответствует его специфицеская CES.
Как работает CCS ?
Очень просто. Пусть у нас есть поток символов ("абстрактных") : "ABBACABCC". Тогда применение CCS к этому потоку (тексту) "ABBACABCC" будет равно применению его CES
к каждому символу в потоке :
CES('A') CES('B') CES('B') CES('A')...
и мы получим поток чисел (кодов) : 61 62 62 61 63 61 62 63 63.
Аналогично, применение CCS к потоку кодов даст поток "абстрактных символов".
Отсюда следует один очень простой вывод : при хранении текста (потока символов) мы должны
также хранить CCS ! А вот где его хранить - это вопрос. Можно в том же потоке ( "In-band" или "MARK-UP" способ). Можно где-то снаружи потока ("Out-band" способ). Можно хранить лишь имя (ссылку на) CCS.
К сожалению, в стандартном POSIX
(например на stdin/stdout) мы имеем только
потоки кодов. А вся информация о CCS
потеряна. Подробнее про это можно прочитать в о локализации POSIX.
Errors
rusconv v.3.11.
Сообщения об ошибках.
error: unrecognized flag 'flag_name'.
ошибка: неизвестный флаг 'имя_флага'.
Проверьте правильность написания флага. Убедитесь, что Вы запускаете правильную версию программы rusconv.
Пример:
rusconv -koi +windows -crlf2cr sample.html
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: unrecognized flag '+windows'.
try 'rusconv -h' or read the manual for help.
error: argument missed after 'define extension'.
ошибка: нет аргумента после флага 'определить расширение'.
define extension: ext, aext, lext, kext, mext, wext
Эта ошибка возникает, если список аргументов заканчивается командой переопределения расширения, а само расширение не указано. Исправляя эту ошибку, не забудьте добавить имена файлов для перевода.
Пример:
rusconv -koi2win -o -ext
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: unrecognized flag '-koi2win'.
try 'rusconv -h' or read the manual for help.
error: 'define extension': extension yet defined.
ошибка: 'определить расширение': расширение уже задано.
define extension: ext, aext, lext, kext, mext, wext
Вы для одной и той же кодировки задаете расширение больше одного раза.
Пример:
rusconv -alt +koi +win +lat -kext k -wext w -wext l readme.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: 'wext l': extension yet defined.
try 'rusconv -h' or read the manual for help.
error: 'define extension': extension too long.
Please use not more than 48 symbols.
ошибка: 'определить расширение': слишком длинное расширение.
Используйте не более 48 символов.
define extension: ext, aext, lext, kext, mext, wext
Вы когда-нибудь видели такие большие расширения?
Пример:
rusconv -u2d -ext 01234567890123456789012345678901234567890123456789
"file.with very long extension"
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: 'ext 01234567890123456789012345678901234567890123456789': extension too long. Please use not more than 48 symbols.
try 'rusconv -h' or read the manual for help.
error: flags '-s' and '-v' can't be used together.
ошибка: флаги '-s' и '-v' вместе использовать нельзя.
Одновременно работать тихо и разговорчиво - это невозможно. Сообщение об ошибке выводится, несмотря на флаг молчания '-s'.
Пример:
rusconv -s -alt +win -v *.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: flags '-s' and '-v' can't be used together.
try 'rusconv -h' or read the manual for help.
0 file(s) converted.
error: flags 'close' and 'noclose' can't be used together.
ошибка: флаги 'close' и 'noclose' вместе использовать нельзя.
Ошибка возникает только в windows-версии. Одновременно позволять и не позволять системе автоматически закрывать окно, в котором запущен rusconv - это невозможно. При данной ошибке окно остается незакрытым, несмотря на флаг 'close'. В dos и unix-версиях эти флаги игнорируются.
Пример:
rusconv -close -u2d -noclose dummy.test
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: flags 'close' and 'noclose' can't be used together.
try 'rusconv -h' or read the manual for help.
error: flags 'alias' and 'alias' can't be used together.
error: flags 'alias' and 'from encoding' can't be used together.
error: flags 'alias' and 'cr2crlf or crlf2cr' can't be used together.
ошибка: флаги 'сокращение' и 'сокращение' вместе использовать нельзя.
ошибка: флаги 'сокращение' и 'из кодировки' вместе использовать нельзя.
ошибка: флаги 'сокращение' и 'cr2crlf или crlf2cr' вместе использовать нельзя.
alias: unix2dos, unix2win, dos2unix, dos2win, u2d, u2w, d2u, d2w
from encoding: '-alt', '-koi', '-mac', '-win'
Сокращение unix2dos (u2d) означает '-koi +alt -cr2crlf', unix2win (u2w) -- '-koi +win -cr2crlf', win2unix (w2u) -- '-win +koi -crlf2cr', dos2unix (d2u) -- '-alt +koi -crlf2cr'. Если Вы используете сокращения, то этим уже задаете, из какой кодировки переводить и как изменять тип концов строк. Сокращения u2d и u2w одновременно использовать можно, так как они не противоречат друг другу.
Пример:
rusconv -u2d -crlf2cr *.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: flags 'unix2dos(u2d)' and 'crlf2cr' can't be used together.
try 'rusconv -h' or read the manual for help.
error: flags 'from encoding 1' and 'from encoding 2' can't be used together.
ошибка: флаги 'из кодировки 1' и 'из кодировки 2' вместе использовать нельзя.
from encoding: '-alt', '-koi', '-mac', '-win'
За один раз Вы можете переводить только из одной кодировки.
Пример:
rusconv -alt -win +koi textfile.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: flags '-alt' and '-win' can't be used together.
try 'rusconv -h' or read the manual for help.
error: flags 'cr2crlf' and 'crlf2cr' can't be used together.
ошибка: флаги 'cr2crlf' и 'cr2crlf' вместе использовать нельзя.
Невозможно одновременно изменять тип концов строк из DOS-формата в UNIX-формат и обратно.
Пример:
rusconv -crlf2cr -cr2crlf +koi textfile.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: flags 'cr2crlf' and 'crlf2cr' can't be used together.
try 'rusconv -h' or read the manual for help.
error: you forgot to specify source encoding.
ошибка: Вы забыли указать, из какой кодировки переводить.
rusconv не знает, в какой кодировке находится текст в файле, поэтому отказывается работать. Однако Вы можете, не изменяя кодировки файла, поменять тип строк из DOS-формата в UNIX-формат и обратно.
Пример:
rusconv -crlf2cr +koi textfile.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: you forgot to specify source encoding.
try 'rusconv -h' or read the manual for help.
error: you forgot to specify target encoding.
ошибка: Вы забыли указать, в какую кодировки переводить.
rusconv не знает, в какую кодировку переводить файл, поэтому отказывается работать. Однако Вы можете, не изменяя кодировки файла, поменять тип строк из DOS-формата в UNIX-формат и обратно.
Пример:
rusconv -alt -crlf2cr textfile.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: you forgot to specify target encoding.
try 'rusconv -h' or read the manual for help.
error: flags 'ext' and 'define extension' can't be used together.
ошибка: флаги 'ext' и 'определить расширение' вместе использовать нельзя.
define extension: aext, lext, kext, mext, wext
Флаг 'ext' заменяет любой из флагов 'aext', 'lext', 'kext', 'mext', 'wext'. При совместном их использовании, расширение для одной и той же кодировки задается дважды. Это запрещено.
Пример:
rusconv -alt +koi +win -kext k.txt -ext w.txt textfile.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: flags 'ext' and 'kext' can't be used together.
try 'rusconv -h' or read the manual for help.
error: only one target encoding can be used with flag 'ext'.
ошибка: при переводе в несколько кодировок нельзя использовать флаг 'ext'.
Рассмотрите приведенный ниже пример. В нем файл data.txt
переводится из альтернативной кодировки в кодировки koi и windows. Результат перевода в каждую из кодировок должен быть сохранен в своем файле. Но в данном случае для обоих файлов задается одно и то же имя data.any.
Пример:
rusconv -alt +koi +win -ext any data.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: only one target encoding can be used with flag 'ext'.
try 'rusconv -h' or read the manual for help.
error: only one target encoding can be used with file overwriting.
ошибка: при переводе в несколько кодировок нельзя использовать перезаписывание файлов.
Результат перевода в каждую из кодировок должен быть сохранен в своем файле. Но при перезаписывании файлов это невозможно.
Пример:
rusconv -alt +koi +win -o data.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: only one target encoding can be used with file overwriting.
try 'rusconv -h' or read the manual for help.
warning: 'argument' is a directory, skipping.
предупреждение: 'аргумент' является директорией, пропускаем его.
В списке файлов для перевода присутствует директория. Она никак не используется. Это предупреждение особенно ценно в UNIX-подобных операционных системах. В них метасимволы раскрывает сама система, при этом имена директорий используются наравне с именами файлов, и результат передается программе.
В данном примере rusconv получит в качестве списка файлов 'dir1 dir2 .'. Директория '.', так как она является последним аргументом, должна содержать переведенные файлы. Директории 'dir1' и 'dir2' пропускается. Получается, что нет файлов для конвертирования. Программа сообщает об этом и завершается.
Пример:
ls -l
drwxrwxr-x 2 w_re w_re 1024 Oct 15 22:55 dir1
drwxrwxr-x 2 w_re w_re 1024 Oct 15 22:55 dir2
rusconv -v -u2w -o dir1 dir2 .
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
warning: 'dir1' is a directory, skipping.
warning: 'dir2' is a directory, skipping.
error: no files to convert.
try 'rusconv -h' or read the manual for help.
0 file(s) converted.
error: file name too long: 'file name'.
ошибка: слишком длинное имя файла: 'имя'.
Полное имя файла (директория, где он находится + имя с расширением) длиннее, чем это позволяет операционная система. Обычно это чуть больше, чем 250. Если Вы получили это сообщение, попытайтесь использовать не полный путь к файлу (например, c:\long-path\...\my-file.txt), а относительный (например, ..\myfile.txt).
Пример:
rusconv -win +alt 0_1_2..._279_280
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: file name too long: '0_1_2..._279_280'.
error: no files to convert.
try 'rusconv -h' or read the manual for help.
0 file(s) converted.
error: file 'file name' does not exists.
ошибка: файл 'имя файла' не существует.
Проверьте, правильно ли Вы написали имя файла и путь к нему. Убедитесь, что файл действительно существует, не является скрытым (hidden) или системным (system). Это сообщение может также появиться и в том случае, если вы задали маску для файлов, а под нее ни один из файлов не подходит.
Пример:
rusconv -u2d dir\nosuch*.file
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: file 'dir\nosuch*.file' does not exists.
error: no files to convert.
try 'rusconv -h' or read the manual for help.
0 file(s) converted.
warning: 'file' is read-only, skipping.
предупреждение: 'файл' только для чтения, пропускаем его.
Это сообщение выдается в режиме перезаписывания файлов. Так как файл только для чтения, изменять его содержимое нельзя.
Пример:
attrib readonly\*.*
A FILE1.TXT .....\readonly\file1.txt
A R FILE2.TXT .....\readonly\file2.txt
rusconv -win2unix -o readonly\*.*
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
warning: 'readonly\file2.txt' is read-only, skipping.
readonly\file1.txt -> .....\readonly\rcE203.TMP -> readonly\file1.txt: ok.
1 file(s) converted.
warning: pattern 'pattern' produce no files.
предупреждение: шаблон 'шаблон' не раскрылся ни в один файл.
Предупреждение выдается, если все файлы, подходящие под шаблон, не включены в список файлов для перевода. Это может быть от того, например, что они системные или скрытые. В UNIX-версии это сообщение не выдается, так как в UNIX раскрытие метасимволов производится системой.
Пример:
attrib readonly\*.*
A R FILE1.TXT .....\readonly\file1.txt
A R FILE2.TXT .....\readonly\file2.txt
rusconv -win2unix -o readonly\*.*
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
warning: 'readonly\file1.txt' is read-only, skipping.
warning: 'readonly\file2.txt' is read-only, skipping.
warning: pattern 'readonly\*.*' produce no files.
error: no files to convert.
try 'rusconv -h' or read the manual for help.
0 file(s) converted.
error: no files to convert.
ошибка: нет файлов для перевода.
Вы забыли указать, какие файлы конвертировать, либо все заданные Вами файлы нельзя преобразовывать. В последнем случае rusconv сообщает, почему нельзя.
Пример:
rusconv -win +alt readme.txt]
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: file 'readme.txt]' does not exists.
error: no files to convert.
try 'rusconv -h' or read the manual for help.
0 file(s) converted.
error: can't make name for temporary file.
ошибка: невозможно создать имя для временного файла.
Для того чтобы получить это сообщение, надо очень постараться. Например, конвертировать файл, находящийся в директории с очень длинным именем. В windows-версии можно также задать режим перезаписывания файлов на дискете, предварительно установив на ней защиту от записи.
Пример:
rusconv -alt +koi -o a:\test
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
a:\TEST: error: can' t make name for temporary file.
0 file(s) converted.
error: can't open file 'file name'.
ошибка: невозможно открыть файл 'имя файла'.
Убедитесь, что этот файл действительно существует на диске. При работе в сети проверьте, что имеете права на чтение из файла.
Пример:
ls -l html/*
--w--w---- 1 w_re w_re 4095 Oct 15 22:58 html/f1.html
--w--w---- 1 w_re w_re 4096 Oct 15 22:58 html/f1.html
--w--w---- 1 w_re w_re 4097 Oct 15 22:58 html/f1.html
rusсonv -w2u -o html/*
error: can't open file 'html/f1.html'.
error: can't open file 'html/f2.html'.
error: can't open file 'html/f3.html'.
error: can't create file 'file name'.
ошибка: невозможно создать файл 'имя файла'.
Диск может быть защищен от записи. Проверьте, что не существует файла с таким именем и с атрибутом 'только для чтения (read-only)'. Убедитесь также, что в имени файла не используется недопустимых символов.
Пример:
rusconv -win +lat -ext win/lat test
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
.\test -> .\test.win/lat: error: can't create file '.\test.win/lat'.
0 file(s) converted.
error: error reading file 'file name'.
ошибка: невозможно прочитать из файла 'имя файла'.
Возможно, файл поврежден. Дальнейшая работа с файлом прекращается. В выходных файлах содержится текст, который был переведен до возникновения ошибки.
Пример:
rusconv -crlf2cr a:\badfile.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
a:\badfile.txt -> .\badfile.cr: error: error reading file 'a:\badfile.txt'.
0 file(s) converted.
error: error writing file 'file name'.
ошибка: невозможно записать в файл 'имя файла'.
Скорее всего, диск, на который производится запись файла, поврежден или переполнен. Дальнейшая работа с текущим файлом прекращается. В выходных файлах содержится текст, который был переведен до возникновения ошибки.
Пример:
rusconv -o -crlf2cr a:\longfile.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
a:\longfile.txt -> A:\rcC094.TMP -> a:\longfile.txt: error: error writing file 'A:\rcC094.TMP'.
0 file(s) converted.
error: can't replace file 'file name' by file 'temporary file'.
ошибка: невозможно файл 'имя файла' заменить файлом 'временный файл'.
Перезапись файлов происходит в три этапа. Вначале исходный файл конвертируется во временный файл. Затем он удаляется. После этого временный файл получает имя исходного файла. Сообщение выводится, если возникла ошибка при удалении или переименовании.
Пример не приводится, так как не удалось добиться появления сообщения.
error: not enough memory.
ошибка: не хватает памяти.
Эта ошибка не должна возникать. Если же все-таки будет получено такое сообщение, действуйте по описанию следующей ошибки, internal error.
Пример не приводится, так как не удалось добиться появления сообщения.
error: sorry, internal error has been detected
in source file 'source file name' on line line number.
please inform us about it by email prof@beta.math.spbu.ru
Это сообщение может возникнуть только лишь из-за ошибок при программировании. Попытайтесь понять, при каких условиях проявляется ошибка, и обязательно сообщите об этом по адресу prof@beta.math.spbu.ru.
Пример не приводится, так как не удалось добиться появления сообщения.
errors.html
Документ создан Паращенко Олегом
Последние изменения - 15 ноября 1998 года
Errors-e
rusconv v.3.11.
List of warnings and error messages.
error: unrecognized flag 'flag_name'.
Check spelling of flags. Make sure that you run right version of rusconv (3.11).
Example:
rusconv -koi +windows -crlf2cr sample.html
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: unrecognized flag '+windows'.
try 'rusconv -h' or read the manual for help.
error: argument missed after 'define extension'.
define extension: ext, aext, lext, kext, mext, wext
This error occurs when list of arguments finished by command of extension defining. When correcting this problem do not forget to add file names for converting.
Example:
rusconv -koi2win -o -ext
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: unrecognized flag '-koi2win'.
try 'rusconv -h' or read the manual for help.
error: 'define extension': extension yet defined.
define extension: ext, aext, lext, kext, mext, wext
You can't define extension for the one encoding twice.
Example:
rusconv -alt +koi +win +lat -kext k -wext w -wext l readme.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: 'wext l': extension yet defined.
try 'rusconv -h' or read the manual for help.
error: 'define extension': extension too long.
Please use not more than 48 symbols.
define extension: ext, aext, lext, kext, mext, wext
Do you ever see such long extensions?
Example:
rusconv -u2d -ext 01234567890123456789012345678901234567890123456789
"file.with very long extension"
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: 'ext 01234567890123456789012345678901234567890123456789': extension too long. Please use not more than 48 symbols.
try 'rusconv -h' or read the manual for help.
error: flags '-s' and '-v' can't be used together.
To walk silently and talkative simultaniously - it is impossible. Message is printed in spite of flag '-s'.
Example:
rusconv -s -alt +win -v *.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: flags '-s' and '-v' can't be used together.
try 'rusconv -h' or read the manual for help.
0 file(s) converted.
error: flags 'close' and 'noclose' can't be used together.
Error can be occured only in windows version. To keep window on desktop and to don't keep - it is impossible. Window with this error printed will not be closed in spite of flag '-close'. In DOS and UNIX versions this flags are ignored.
Example:
rusconv -close -u2d -noclose dummy.test
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: flags 'close' and 'noclose' can't be used together.
try 'rusconv -h' or read the manual for help.
error: flags 'alias' and 'alias' can't be used together.
error: flags 'alias' and 'from encoding' can't be used together.
error: flags 'alias' and 'cr2crlf or crlf2cr' can't be used together.
alias: unix2dos, unix2win, dos2unix, dos2win, u2d, u2w, d2u, d2w
from encoding: '-alt', '-koi', '-mac', '-win'
Abbreviation unix2dos (u2d) means '-koi +alt -cr2crlf', unix2win (u2w) -- '-koi +win -cr2crlf', win2unix (w2u) -- '-win +koi -crlf2cr', dos2unix (d2u) -- '-alt +koi -crlf2cr'. If you use abbreviations you automatically defines source encoding and how to change type of end of lines. You can use flags u2d and u2w because they are not contadictory.
Example:
rusconv -u2d -crlf2cr *.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: flags 'unix2dos(u2d)' and 'crlf2cr' can't be used together.
try 'rusconv -h' or read the manual for help.
error: flags 'from encoding 1' and 'from encoding 2' can't be used together.
from encoding: '-alt', '-koi', '-mac', '-win'
You can specify only one source encoding.
Example:
rusconv -alt -win +koi textfile.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: flags '-alt' and '-win' can't be used together.
try 'rusconv -h' or read the manual for help.
error: flags 'cr2crlf' and 'crlf2cr' can't be used together.
It is impossible to change type of line ends from DOS format to UNIX format and back simultaniouosly.
Example:
rusconv -crlf2cr -cr2crlf +koi textfile.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: flags 'cr2crlf' and 'crlf2cr' can't be used together.
try 'rusconv -h' or read the manual for help.
error: you forgot to specify source encoding.
Rusconv don't know from what encoding to convert. But you can change type of line ends without changing of encoding.
Example:
rusconv -crlf2cr +koi textfile.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: you forgot to specify source encoding.
try 'rusconv -h' or read the manual for help.
error: you forgot to specify target encoding.
Rusconv don't know to what encoding to convert. But you can change type of line ends without changing of encoding.
Example:
rusconv -alt -crlf2cr textfile.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: you forgot to specify target encoding.
try 'rusconv -h' or read the manual for help.
error: flags 'ext' and 'define extension' can't be used together.
define extension: aext, lext, kext, mext, wext
Flag 'ext' is interpreted as one of flags 'aext', 'lext', 'kext', 'mext', 'wext'. So if you use this flag and its interpretation then you defines extension for encoding twice. It is incorrect.
Example:
rusconv -alt +koi +win -kext k.txt -ext w.txt textfile.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: flags 'ext' and 'kext' can't be used together.
try 'rusconv -h' or read the manual for help.
error: only one target encoding can be used with flag 'ext'.
Consider next example. Here file data.txt
is converted from alternative encoding to KOI and windows encodings. Results should be placed in different files. But in this example names for both files are the same - 'data.any'.
Example:
rusconv -alt +koi +win -ext any data.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: only one target encoding can be used with flag 'ext'.
try 'rusconv -h' or read the manual for help.
error: only one target encoding can be used with file overwriting.
Results of converting should be placed in different files. But in mode of overwriting files it is impossible.
Example:
rusconv -alt +koi +win -o data.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: only one target encoding can be used with file overwriting.
try 'rusconv -h' or read the manual for help.
warning: 'argument' is a directory, skipping.
List of file contains directory. Rusconv skips this argument. This warning is very valuable in UNIX-like systems where work with metachars is a duty of operating system which use directory names and file names equally. So rusconv can get directory in argument list.
In next example rusconv gets as a file list 'dir1 dir2 .'. Last directory in list is a output directory. Directories 'dir1' and 'dir2' are skipped. So there is no files to convert.
Example:
ls -l
drwxrwxr-x 2 w_re w_re 1024 Oct 15 22:55 dir1
drwxrwxr-x 2 w_re w_re 1024 Oct 15 22:55 dir2
rusconv -v -u2w -o dir1 dir2 .
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
warning: 'dir1' is a directory, skipping.
warning: 'dir2' is a directory, skipping.
error: no files to convert.
try 'rusconv -h' or read the manual for help.
0 file(s) converted.
error: file name too long: 'file name'.
Full file name (file directory + name with extension) is longer then allowed by operating system. Usually it is near 250 bytes. If you get this message try to use instead of full path (for example, c:\long-path\...\my-file.txt) relative path (for example, ..\myfile.txt).
Example:
rusconv -win +alt 0_1_2..._279_280
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: file name too long: '0_1_2..._279_280'.
error: no files to convert.
try 'rusconv -h' or read the manual for help.
0 file(s) converted.
error: file 'file name' does not exists.
Check you spelling, make sure that file is really exists and is not hidden or system. This message also can be printed if you use metachars and no any appropriate file was found.
Example:
rusconv -u2d dir\nosuch*.file
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: file 'dir\nosuch*.file' does not exists.
error: no files to convert.
try 'rusconv -h' or read the manual for help.
0 file(s) converted.
warning: 'file' is read-only, skipping.
This message is printed in mode of file overwriting. File is read-only, so rusconv shouldn't change its content.
Example:
attrib readonly\*.*
A FILE1.TXT .....\readonly\file1.txt
A R FILE2.TXT .....\readonly\file2.txt
rusconv -win2unix -o readonly\*.*
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
warning: 'readonly\file2.txt' is read-only, skipping.
readonly\file1.txt -> .....\readonly\rcE203.TMP -> readonly\file1.txt: ok.
1 file(s) converted.
warning: pattern 'pattern' produce no files.
This message is printed when no any appropriate file was added to converting list. It can be if, for example, this files are hidden or system. This message is absent in UNIX version because in UNIX work with metachars is a duty of operating system.
Example:
attrib readonly\*.*
A R FILE1.TXT .....\readonly\file1.txt
A R FILE2.TXT .....\readonly\file2.txt
rusconv -win2unix -o readonly\*.*
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
warning: 'readonly\file1.txt' is read-only, skipping.
warning: 'readonly\file2.txt' is read-only, skipping.
warning: pattern 'readonly\*.*' produce no files.
error: no files to convert.
try 'rusconv -h' or read the manual for help.
0 file(s) converted.
error: no files to convert.
Check that you write file list. Also it is possible that items of file list are ignored due some reasons.
Example:
rusconv -win +alt readme.txt]
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
error: file 'readme.txt]' does not exists.
error: no files to convert.
try 'rusconv -h' or read the manual for help.
0 file(s) converted.
error: can't make name for temporary file.
It is a very difficult to get this message. In windows version this possible if you specify file overwriting on write-protected disk A:\.
Example:
rusconv -alt +koi -o a:\test
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
a:\TEST: error: can't make name for temporary file.
0 file(s) converted.
error: can't open file 'file name'.
Check that file is really exists. If you work in network make sure that you have read writes.
Example:
ls -l html/*
--w--w---- 1 w_re w_re 4095 Oct 15 22:58 html/f1.html
--w--w---- 1 w_re w_re 4096 Oct 15 22:58 html/f1.html
--w--w---- 1 w_re w_re 4097 Oct 15 22:58 html/f1.html
rusconv -w2u -o html/*
error: can't open file 'html/f1.html'.
error: can't open file 'html/f2.html'.
error: can't open file 'html/f3.html'.
error: can't create file 'file name'.
Disc may be write-protected. Make sure that don't exists file with the same name but with attribute 'read-only'. Check that you don't use not allowed symbols in file name.
Example:
rusconv -win +lat -ext win/lat test
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
.\test -> .\test.win/lat: error: can't create file '.\test.win/lat'.
0 file(s) converted.
error: error reading file 'file name'.
File may be damaged. Rusconv finishes any work with this file. Output files will have text which was converted before error occured.
Example:
rusconv -crlf2cr a:\badfile.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
a:\badfile.txt -> .\badfile.cr: error: error reading file 'a:\badfile.txt'.
0 file(s) converted.
error: error writing file 'file name'.
Disc where file is placed may be damaged or full. Rusconv finishes any work with this file. Output files will have text which was converted before error occured.
Example:
rusconv -o -crlf2cr a:\longfile.txt
** rusconv -- convertor of Russian codepages, v.3.11.
** (c)w_re -- Oleg A. Paraschenko http://beta.math.spbu.ru/~prof/w_re/
a:\longfile.txt -> A:\rcC094.TMP -> a:\longfile.txt: error: error writing file 'A:\rcC094.TMP'.
0 file(s) converted.
error: can't replace file 'file name' by file 'temporary file'.
Overwriting of file consist of three stages. In first stage source file converts to temporary file. When source file deleted. On last stage temporary file receive name of source file. This message is printed if error occured during this stages.
We can't get this message, so no example.
error: not enough memory.
This error should not be happen. See description of next error, 'internal error'.
We can't get this message, so no example.
error: sorry, internal error has been detected
in source file 'source file name' on line line number.
please inform us about it by email prof@beta.math.spbu.ru
This error should not be ever happen. A lot of testing maked rusconv very stable. But if you get this message try collect as much as possible information when and why its happen. Then send us E-MAIL with description (address is prof@beta.math.spbu.ru).
We can't get this message, so no example.
errors-e.html
Document created by Oleg A. Paraschenko
Last changes - 15 November 1998
Еще раз о ссылках
latex2html берет на себя заботу практически обо всех проблемах, возникающих при преобразовании файла LaTeX в набор html-файлов. Однако ссылки на другие части того же документа или на другие документы концептуально отличаются в печатной документации и HTML. Рассмотрим следующий фрагмент LaTeX
Ниже мы обобщим наши результаты, используя цилиндрическую систему координат. Смотрите определение координатной системы на странице~\pageref{definition:coordinate-system}.
в котором LaTeX послушно заменяет \pageref{definition:coordinate-system} номером страницы, ка которой находится метка \label{definition:coordinate-system} В чем проблема? Первое, у набор страниц html нет твердо определенного понятия "номерстраницы". Во-вторых, latex2html заменяет \pageref{definition:coordinate-system} ссылкой на то место, где отображается сответствующая \label{definition:coordinate-system} часть документа. Эта метка отображается темным квадратом в графическом браузере или маркером "[*]" в текстовых браузерах. Такая конструкция выглядит неуклюже, почти мешает, но это не вина latex2html:
Ниже мы обобщим наши результаты, используя цилиндрическую систему координат. Смотрите определение координатной системы на странице [*].
Latex2html нуждается в нашей помощи! Для экранной версии, абзац с ссылкой нужно перефразировать, например так:
Ниже мы обобщим наши результаты, используя <a>цилиндрическую систему координат<</a>>.
где мы указали гиперссылку с помощью anchor-тэгов HTML. Для того, чтобы было возможным создавать различные версии в зависимости от выходного формата, в latex2html определена команда \hyperref.
\hyperref[тип-ссылки]{текст для html-версии}{текст, предшествующий ссылке в LaTeX-версии}{текст, следующий за ссылкой в LaTeX версии}
Необязательный параметр тип-ссылки устанавливает, какой счетчик будет использоваться ссылкой:
"ref" Перекрестная ссылка на номер раздела, как в команде \ref. Текстом ссылки становится номер секции ("4", "1.5.2", "3.4.2.1" и т.д). "page" или "pageref" Ссылается на номер страницы, как \pageref. Текстом ссылки становится номер страницы ("25", "xxiii" и т.д).
Вот наш пример, переписанный с использованием \hyperref
Ниже мы обобщим наши результаты, используя \hyperref[pageref]% {цилиндрическую систему координат}% для HTML {цилиндрическую систему координат. Смотрите% для LaTeX определение координатной системы на странице~} {}% завершающий текст для LaTeX, в переводе пуст {definition:coordinate-system}.% метка, на которую ссылается ссылка
LaTeX преобразует это так
Ниже мы обобщим наши результаты, используя цилиндрическую систему координат. Смотрите определение координатной системы на странице 97.
а latex2html создает
Ниже мы обобщим наши результаты, используя цилиндрическую систему координат.
после обработки того же исходного текста.
Файлы .nedit и .neditdb
Не факт, что возникнет необходимость их ручной правки, но полноты картины для вкратце опишу их структуру.
Содержание файла .nedit составляет описание тех самых параметров, которые настраиваются через главное меню Preferences - Default Settings. К коему и следует, как гласит комментарий, прибегать для его изменения. Тем не менее он доступен и для ручного редактирования, что, как и всякую свободу выбора, следует расценить только положительно.
Начальная (после комментариев) строка файла - указание на номер версии: nedit.fileVersion: 5.1
Затем следуют секции описания настраиваемых меню Shell, Macro и контекстного: nedit.shellCommands: \ spell:Alt+B:s:EX:\n\ ... nedit.macroCommands: \ Headers>header1:F1::: {\n\ ... nedit.bgMenuCommands: \ Undo:::: {\n\ ...
соответственно. Описывать их содержимое я не буду. Скажу только, что первая строка после заглавия секции содежит название скрипта или макроса (в том самом виде, как оно отображается в соответствующем меню (так, для приведенного макроса - двухуровневом, Headers>header1). Затем, разделяясь двоеточиями, следуют всякого рода дополнительные сведения, такие, как закрепленная клавишная комбинация или мнемоническое обозначение.
Следующие секции nedit.highlightPatterns: C:Default\n\ C++:Default\n\ ... nedit.languageModes: C:.c .h::::::".,/\\`'!|@#%^&*()-=+{}[]"":;<>?~"\n\ C++:.cc .hh .C .H .i .cxx ... nedit.styles: Plain:black:Plain\n\ Comment:gray20:Italic\n\ ...
определяет разнообразные параметры (подсветка, отступы и т.д.) для различных языковых режимов.
За этим следуют опции переноса слов, автоматических осттупов, подсветки синтаксиса и прочие, подробно рассмотренные выше, в разделе о настройке через меню, смысл их достаточно прозрачен. Завершающие разделы - поисание геометрии открываемого окна, шрифтов редактируемого текста и т.д., - также не должны вызвать вопросов. И посему, скажем, при необхоимости можно изменить, например, кегль шрифта, не обращаясь к меню. Другое дело, что вряд ли такая необходимость возникнет...
Ну а файл .neditdb - это просто список (задумичво называемый базой данных) ранее открывавшихся файлов с указанием полных абсолютных путей. Что характерно, в списке пункта меню File - Open Previous они даются без дублирования - все же буквы db в названии присутствуют не зря.
Faq
rusconv v.3.11.
Полезные советы и ответы на типичные вопросы.
Содержание:
Как сделать, чтобы операционная система сама находила и запускала программы rusconv и whatrus?
Какие файлы можно конвертировать с помощью rusconv?
Для чтения почты используется Netscape. Пришло письмо в неправильной кодировке. Что делать?
С помощью Netscape Composer (или Frontpage, или еще какого-либо HTML-редактора) была создана HTML-страничка в кодировке windows. Rusconv преобразовал ее в кодировку КОИ-8. Почему вместо русского текста обозреватель выводит мусор?
На концах строк находятся странные символы. Как их убрать?
Можно ли использовать исходные тексты rusconv в своих программах?
Как лучше всего сделать ссылку на rusconv со своей HTML-странички?
Как сделать, чтобы операционная система сама находила и запускала программы rusconv и whatrus?
В DOS и windows создайте какой-нибудь каталог, в котором будут находиться rusconv и whatrus, например, C:\UTIL. Скопируйте в него rusconv и whatrus. Отредактируйте файл C:\AUTOEXEC.BAT: в нем в переменную PATH добавьте директорию C:\UTIL. Для этого проще всего на последней строке файла написать команду
PATH=%PATH%;C:\UTIL
После перезагрузки, rusconv и whatrus можно будет запустить из любой директории.
В UNIX, если Вы являетесь системным администратором, rusconv и whatrus лучше всего скопировать в директорию /usr/local/bin. Тогда эти утилиты будут доступны всем пользователям. Если же у Вас нет прав на это, то можно создать в своем домашнем каталоге директорию bin и скопировать программы туда. Обычно переменная PATH настроена правильно и содержит эту директорию. В противном случае, надо отредактировать файл начальных установок (скорее всего, ~/.bashrc) и повторно войти в систему.
Какие файлы можно конвертировать с помощью rusconv?
С помощью rusconv можно конвертировать любые файлы, содержащие текст. Среди них - '.txt', '.html', '.tex', '.rtf',
исходные тексты программ и другие. Документы (.doc-файлы), создаваемые с помощью Microsoft Word, не являются текстовыми, и при использовании rusconv могут быть испорчены.
Для чтения почты используется Netscape. Пришло письмо в неправильной кодировке. Что делать?
Вначале надо просто поменять кодировку, используемую для просмотра почты. Если это не помогает, создаем новую папку с письмами (File->New Folder...). Называем ее, например, recover и копируем в нее письмо. Смысл всего этого в том, что создается файл с именем типа C:\Program files\Netscape\Users\<Ваше имя>\mail\recover. Он содержит сообщение в том виде, в котором его получил Netscape и, что самое главное, этот файл - текстовый. Теперь можно определить его кодировку, и с помощью rusconv привести его к читаемому виду.
Лучше всего перевести текст в ту кодировку, в которой он был отправлен. Тогда Netscape будет выводить письмо правильно. Чтобы определить исходную кодировку, нужно открыть файл 'recover' и найти в нем строчку типа Content-type: text/plain; charset=koi8-r.
С помощью Netscape Composer (или Frontpage, или еще какого-либо HTML-редактора) была создана HTML-страничка в кодировке windows. Rusconv преобразовал ее в кодировку КОИ-8. Почему вместо русского текста обозреватель выводит мусор?
С помощью специальных тегов можно сказать обозревателю, какой набор символов использовать для вывода HTML-страницы. Причем отказаться от него невозможно - что бы Вы ни выбрали в меню View->Encoding, будет использоваться все равно он.
Большинство HTML-редакторов автоматически добавляют команду задания кодировки. Если сконвертировать файл вне этого редактора, то страничка окажется в другой кодировке, а команда останется без изменения. Из-за этого в данном примере обозреватель использует кодировку windows для отображения странички в КОИ-8. Неудивительно, что вместо текста выводится мусор.
Один из вариантов решения проблемы - переводить HTML-файл в самом редакторе (если он это позволяет). Другой путь - использовать rusconv для конвертирования, а затем в новой версии файла найти строку
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=windows-1251">
и заменить поле charset на правильное (например, koi8-r). Но лучше всего - удалить эту строку.
На концах строк находятся странные символы. Как их убрать?
Первый вариант. Вы работаете в операционный системе UNIX. Возможно, в тексте используется DOS/windows-формат кодирования концов строк. Чтобы преобразовать файл в UNIX-формат, используйте флаг 'crlf2cr'.
Второй вариант. Вы работаете в DOS или windows. Возможно, вы случайно изменили тип концов строк из UNIX-формата в DOS-формат, причем строки уже были в DOS-формате. Для исправления файла запустите rusconv дважды - вначале с флагом '-crlf2cr', а затем с флагом '-cr2crlf'.
Третий вариант. Тип концов строк ни при чем. В этом случае удалить лишние символы можно вручную.
Можно ли использовать исходные тексты rusconv в своих программах?
Вносить изменения в исходные тексты и создавать свои версии программ rusconv и whatrus - нельзя. Но использовать части кода в своих проектах - можно. При этом желательно указать в документации, что использованы исходные тексты rusconv или whatrus, а также дать адрес web-узла rusconv (http://beta.math.spbu.ru/~prof/w_re/).
Как лучше всего сделать ссылку на rusconv со своей HTML-странички?
Как Вам больше нравится. Адрес web-узла rusconv:
http://beta.math.spbu.ru/~prof/w_re/
По умолчанию загрузится windows-версия. Начальные странички в других кодировках имеют адреса:
http://beta.math.spbu.ru/~prof/w_re/index.html - windows http://beta.math.spbu.ru/~prof/w_re/index-k.html - КОИ-8 http://beta.math.spbu.ru/~prof/w_re/index-l.html - latinica http://beta.math.spbu.ru/~prof/w_re/index-e.html - english
Приятной работы!
faq.html
Документ создан Паращенко Олегом
Последние изменения - 15 ноября 1998 года
Faq-e
rusconv v.3.11 -- tips and tricks.
Content:
How to tune operating system to find and run rusconv and whatrus from any directory?
What types of files can be converted by rusconv?
For mail reading I use Netscape. What to do if I receive mail in incorrect encoding?
I created HTML page in Netscape Composer (or in Frontpage or in any other HTML editor) in windows encoding. Rusconv converted it to encoding KOI-8. Why browser don't show russian text properly?
There are funny chars at the end of lines. How to remove them?
Can I use rusconv and whatrus sources in my own programs?
What is the best way to make link on rusconv's web site?
How to tune operating system to find and run rusconv and whatrus from any directory?
In DOS and Windows create any directory where rusconv and whatrus will be placed, C:\UTIL for example. Edit file C:\AUTOEXEC.BAT: add directory C:\UTIL to variable PATH . The simplest way to do it is to add this line at the end of file:
PATH=%PATH%;C:\UTIL
After computer reloaded, rusconv and whatrus can be run from any directory.
In UNIX if you are a system administrator the best way is to copy rusconv and whatrus to directory /usr/local/bin. When this utilities will be accessed by any user. If you have no rights to do this, create directory bin in you home directory and copy programs there. Usually environment variable PATH is set properly and contains this directory. Otherwise edit your startup file (usually ~/.bashrc) and relogin.
What types of files can be converted by rusconv?
Rusconv can convert any files which contain text. They are '.txt', '.html', '.tex', '.rtf', sources of programs and other. Documents (.doc-files), which created by Microsoft Word, are not text files and can be damaged by rusconv.
For mail reading I use Netscape. What to do if I receive mail in incorrect encoding?
First of all change encoding used for mail reading. If it does not help try another method. Create new mail folder (File->New Folder...). Call it, for example, recover and copy mail there. After this file with name like C:\Program files\Netscape\Users\<your name>\mail\recover
will be created. It contains message in a plain text. Now you can detect and convert encoding in this file.
The best encoding to convert to is one in which mail was sent. Then Netscape will show message properly. To detect the source encoding open file 'recover' and find line like Content-type: text/plain; charset=koi8-r.
I created HTML page in Netscape Composer (or in Frontpage or in any other HTML-editor) in windows encoding. Rusconv converted it to encoding KOI-8. Why browser don't show russian text properly?
Special tags can specify what charset to use for viewing HTML page. This charset will be used even if you choose another one in menu View->Encoding.
Most part of HTML editors automatically add tag which defines encoding of page. If you convert page outside editor then page will be in another encoding but tag will specify old charset. In this example browser use windows encoding to show KOI-8 version of the page. So it is not surprising that browser don't show russian text properly.
One way to solve this problem is to convert HTML file inside the editor (if it is allowed). Another way is convert file by rusconv and then in new version of file find line
<META HTTP-EQUIV="Content-Type" CONTENT="text/html; charset=windows-1251">
and change field charset properly (for example, to koi8-r). But the best of all is to delete this line.
There are funny chars at the end of lines. How to remove them?
First variant. You use UNIX. May be text is in DOS/windows format of end of lines. To convert it to UNIX format use flag 'crlf2cr'.
Second variant. You use DOS or windows. May be you occasionally change type of end of lines from UNIX to DOS format but lines yet were in DOS format. To undo changes run rusconv twice - one time with flag '-crlf2cr' and then with flag '-cr2crlf'.
Third variant. The matter is not in the type of end of lines. In this case delete unnecessary chars manually.
Can I use rusconv and whatrus sources in my own programs?
You are not allowed to change sources and create you own versions of rusconv and whatrus. But you can use parts of code in you own projects. Please do not forget to make reference to rusconv and whatrus and to rusconv's web site (http://beta.math.spbu.ru/~prof/w_re/).
What is the best way to make link on rusconv's web site?
It is your choose. Address of rusconv's web site is
http://beta.math.spbu.ru/~prof/w_re/
By default russian version in windows encoding will be loaded. Start pages in other encodings are
http://beta.math.spbu.ru/~prof/w_re/index.html - windows http://beta.math.spbu.ru/~prof/w_re/index-k.html - KOI-8 http://beta.math.spbu.ru/~prof/w_re/index-l.html - latinica http://beta.math.spbu.ru/~prof/w_re/index-e.html - english
Have a nice work!
faq-e.html
Document created by Oleg A. Paraschenko
Last changes - 15 November 1998
Feedback
rusconv v.3.11 -- обратная связь
Здесь Вы можете зарегистрироваться или высказать свои впечатления от программы rusconv. Если Вы не против, ответьте на наши вопросы. Благодаря полученным сведениям, мы сможем улучшить rusconv и сделать его более популярным.
Представьтесь, пожалуйста:
Ваше имя:
Ваш E-MAIL:
Вы хотите:
зарегистрироваться высказать свои впечатления
Ваши впечатления от rusconv:
Какую операционную систему Вы используете?
DOS Windows UNIX Другую:
Для чего Вы используете или планируете использовать rusconv (создание собственной Web-странички, ...)?
Как Вы узнали про rusconv?
С помощью поисковой машины. Нашел ссылку на rusconv с shareware/freeware-сервера. Rusconv был на компакт-диске с утилитами. Взял у знакомого. Случайно наткнулся на rusconv при путешествии по сети. Расскажите подробнее:
Используете ли Вы другие перекодировщики? Какие? Чем они лучше/хуже? Чего не хватает в rusconv?
Нажмите на эту кнопку, чтобы отправить форму:
ПРИЯТНОЙ РАБОТЫ!
feedback.html
Документ создан Паращенко Олегом
Последние изменения - 15 ноября 1998 года
Feedback-e
rusconv v.3.11 -- feedback
Here you can register, put suggestions, wishes, comments on rusconv. We would like if you answer some questions. You answers help us to make rusconv better and more popular.
Write some information about you, please:
Your name:
Your E-MAIL:
You wish:
register put comments
Comments:
What operating system do you use?
DOS Windows UNIX Other:
For what tasks do you use rusconv (creating web site, ...)?
How do you get rusconv?
Take a link from search engine. Take a link from shareware/freeware server. Rusconv was on CD with utilities. Rusconv was recommended by a friend. Found occasionly when was working in Internet. Write more:
Do you use other decoders? Which? Why they are better/worse? What should be added to rusconv?
Press this button to send form:
HAVE A NICE WORK!
feedback-e.html
Document created by Oleg A. Paraschenko
Last changes - 15 November 1998
Феньки всякие
M-x doctor psy hanoi Психотерапевт. Психотерап. сеанс. Пирамидка M-x calendar Календарь М-/ Развернуть слово до ближайшего похожего в буфере.
File
Он включает в себя в основном обычные файловые операции, как то:
создание файла (New, Ctrl+N), сопровождаемое открытием нового окна, относящегося, тем не менее, к текущему сеансу NEdit; открытие файла (Open, Ctrl+O), в том числе выделенного (Open Selected, Ctrl+Y) и из списка последних (Open Previous), количество которых настраиваемо (см. далее); как и при создании файла, каждый документ открывается в своем собственном окне; закрытие файла (Close Ctrl+W); в случае его модификации по умолчанию следует запрос на запись изменений, а также установок по умолчанию, если они изменялись; сохранение файла (Save Ctrl+C), в том числе и под другим именем (Save as); последняя опция позволяет сохранить текстовый файл не только в формате Unix (с LF в качестве символа возврата каретки), но и формате DOS (он же Windows), где в этом качестве применяется CR-LF; возможно также дополнение строк, оборванных при включении переноса слов (о чем будет разговор в разделе о настройках), до полного абзаца, завершаемого нажатием клавиши Enter (Add line breaks where wrapped); уникальная опция отмены изменений в уже записанном файле (Revert to Saved); вставка некоего существующего файла в текущий документ (Include File, Alt+I), осуществляемая в позиции курсора; открытие файла макросов или тэгов (Load Macro File и Load Tags File, соответственно), о чем подробнее - ниже; печать текущего файла (Print, Ctrl+P) или выделенного фрагмента (Print Selection); выход из программы (Exit, Ctrl+Q).
Переходим у пункту второму -
ФИЛЬТРЫ
M-x outline-mode to turn on Outline mode in the current buffer. set-var outline-regexp по умолчанию ^[*][*]* задает фильтр M-x hide-body Спрятать все кроме заголовков M-x show-all Включить все строки
Фирмы - производители программного обеспечения.
Netscape Internationalization Secrets (Netscape)
MSDN Going Global (Microsoft)
Universal Localization Program (Mozilla)
JDK Internationalization Overview (Java)
The Java Toutorial. Internationalization.
Inside Macintosh: Text (Apple)
Digital (Compaq?) Unix :
IBM AIX :
Hewlett Packard HP-UX Operating System
Физическая разметка [Inline Markup]
LaTeX предоставляет богатейшие возможности физической разметки, меняющей внешний вид текста. Здесь я ограничусь обсуждением лишь тех трех команд, которые уже упоминались при обсуждении формат "Старой, доброй и простой документации Perl" [Perl's plain old documentation]: выделения (эмфазы), курсива, полужирного и машинописного стиля шрифта.
Выделение и Курсив \textit{аргумент} -- Печатает аргумент текстовым курсивом. \emph{аргумент} -- Производит выделение аргумента. По умолчанию, в зависимости от текущих установок шрифта, включает/выключает курсивное или наклонное начертание. Если текущее начертание прямое, то команда \emph включает курсивное начертание, если же текущая установка -- курсив, то эта команда устанавливает прямое начертание шрифта. Таким образом выделенный текст всегда бросается в глаза. Полужирный шрифт \textbf{аргумент} -- выводит аргумент полужирным шрифтом. На основе команды \textbf мы можем определять свои собственные команды логической разметки, например так: \newcommand{\important}[1]{\textbf{#1}}
Машинописный шрифт \texttt{аргумент} -- выводит аргумент на печать моноширинным "машинописным" шрифтом. Как и \textbf, \texttt можно "заворачивать" в определенные пользователем команды: \newcommand{\sourcecode}[1]{\texttt{#1}}
Fonts
| ИЗДАТЕЛЬСКИЕ СИСТЕМЫ | |||
| Шрифты и вы - кто кого?
Любой шрифт, так же как и любой цвет, имеет свою тональность, свое настроение. Все знают о выгодных, гармоничных сочетаниях цветов и постоянно пользуются этим знанием - ведь мы одеваемся каждый день? А на что способно верное сочетание шрифтов?  | Гармоничный выбор преобразит вашу работу: ведь каждый шрифт - это настроение, эпоха, сила. И эти определения невольно передаются тексту, заставляя нас изначально предвзято относиться к прочитанному. Я сегодня расскажу вам об истории основных видов шрифтов, формы букв которых используются и по сегодняшнее время. Мы также рассмотрим факторы, влияющие на удобство чтения и правильное восприятие набранных нами текстов. Из истории: классическая антиква Это самые старые из используемых сейчас видов - их рождение приходится на эпоху Возрождения. Не забыты при этом и родители - рукописные шрифты IX-XIII веков. Эти шрифты могут создать строгий, изящный, легко читаемый текст, отвечающий ренессансным представлением о гармонии. В большинстве случаев легкий дух Высокого Возрождения придаст стильное, выпуклое, воздушное звучание тончайшим смысловым и эмоциональным оттенкам вашего текста. Переходные шрифты В XVIII веке - сначала в Англии, затем и по всей Европе - формы букв становятся строже, прямолинейнее, стандартизованные (отчасти это объясняется развитием техники книгопечатания), а контраст между толщиной вертикальных и горизонтальных штрихов увеличивается. Этот период, продолжающий тенденции развития поздней классической антиквы, принято называть переходным, и в нем лежат истоки таких широко употребляемых сейчас шрифтов, как Таймс и Баскервилль, - их объединяют названием переходная антиква. Эти шрифты отличаются линейностью штрихов, однотипными закруглениями по дугам окружностей, короткими и острыми на концах засечками. Пропорции букв наиболее "прозрачны", естественны для современного восприятия. Но в связи с тем, что шрифт Таймс стандартный для Windows, он приелся частым использованием. Изначально формы этих шрифтов разрабатывались для наименьшей заметности, чтобы взгляд человека при чтении не отвлекался на посторонние элементы. Новая антиква В конце XVIII века появился новый тип шрифтов, который сразу же завоевал широкое признание и безраздельно господствовал в печатной продукции XIX века, - шрифты новой антиквы. Для шрифтов этой группы характерен прежде всего высокий контраст между толщиной вертикальных и горизонтальных штрихов и тонкие длинные засечки, соединяющиеся с основным штрихом без закруглений. Общий очерк букв - определенно сухой, вычурный, нарочитый. Форма букв - как бы специально эстетская - с претензией. И первая стойкая ассоциация - английский, педантичный шрифт (и текст, им набранный...). Новые рубленые Эти шрифты произвели фурор и безраздельно господствовали в книгах первой половины ХХ века: подчеркнуто упрощенные и геометризованные формы были очень непривычны и новы. Создатели руководствовались возведенным в принцип утилитаризмом, последовательным отказом от любых не несущих практической нагрузки "украшений". Самый известный пример - шрифт Футура, появившийся в 1928 году. Каждая буква Футуры изо всех сил стремится к некоему геометрическому идеалу. Такому шрифту нельзя отказать в единстве и определенном своеобразии, но он весьма утомителен в больших объемах. Хотя заголовки выглядят очень мягко и современно. Перечисленные группы шрифтов являются основными при наборе больших по объему текстов. Мы не учитывали декоративные шрифты, хотя без них обойтись вовсе нельзя, но их сложно классифицировать. И потом, используя их, вы вряд ли добьетесь строгости и ясности дизайна своих текстовых творений. О правилах набора, или Подарит ли вам верстальщик цветы? Правила эти общеизвестны, и мы повторим их лишь вкратце. Во-первых, чтобы верстальщик не перегрыз вам горло (а если вы девушка, чтобы не было у верстальщика повода пригласить вас на свидание поздно вечером, в дождь, а самому не прийти), всегда проверяйте свой труд на наличие 2 и более пробелов подряд. Вам это может показаться мелочью, но, когда при верстке колонками мы получаем "дыры" в тексте, поверьте, радуемся безмерно (особенно, если не сняли премию). Это правило 2 подряд пробелов имеет и еще одно замечательное, неочевидное продолжение: многие девушки, набирая текст, добиваются пробелами "загона" заголовка в центр при выключке влево. При этом они сознательно ставят много (часто больше 20) пробелов подряд. Никогда, никогда так не делайте! Во-вторых, пробел со знаками препинания всегда должен выглядеть так: до - никогда, после - всегда. В-третьих, тире никогда не равно минусу (-), а всегда равно либо Alt-0150 (нажимаем сначала левую кнопку и, не отпуская ее, на цифровой клавиатуре справа набираем "телефон" этого тире), и тогда это выглядит так (-), либо берем тире подлиннее (его "телефон" - Alt-0151). В-четвертых, кавычки используем в официальных текстах только типографские, вот такие "кавычки-елочки" (Alt-0171 для " и Alt-0187 для "). А в неофициальных текстах, мне кажется, более уместны менее "тяжелые" кавычки с "телефонами" Alt-0147 и Alt-0148 (смотрите внимательно: "кавычки-не-елочки"). В-пятых, никогда не добиваемся от Word, чтобы он переносил нам текст на следующую страницу пробелами и "концами абзаца" (они получаются, если нажимать Enter). Есть гораздо более миролюбивый (не делайте из верстальщика зверя) способ: устанавливаете курсор в начало той строки, какую вам надо увидеть именно на следующей странице, и идете "в гости" в верхнюю, командную строку вашего текстового редактора "Вставка", затем там же "Разрыв" и далее следуете инструкциям. В-шестых, старайтесь выражаться предложениями с малым количеством слов. Ну и, в-седьмых, полюбите своего верстальщика. И тогда он многое вам простит. (Работа у него такая - прощать...) Что позволено быку, или Как долго мы употребляем печатную продукцию Плакат - от 3 секунд (рекламное правило 3 секунд) до 5 минут. Газета - от 1 дня до 1 недели. Журнал - от 1 месяца до 1 года (научные - 3-5 лет). Книга - 1-5 веков. А значит, для газеты важен экономичный дизайн, позволяющий легко манипулировать информацией и ее объемами. Для журнала важен стиль, который бы выделял его среди прочих, а также следование моде и тому подобные соображения. В книге важна традиционность и удобочитаемость, сдержанное употребление модных приемов, так как на нее будут смотреть многие поколения после вас. Плакат же должен привлекать внимание, какие бы аморальные средства для этого ни использовались, вплоть до полного поругания удобочитаемости. Однако в жизни мы встречаем газеты, которые превосходят качеством оформления многие журналы. Встречаем журналы, выходящие еженедельно, то есть являющиеся почти газетами. Книги-боевики, рассчитанные на то, чтобы после прочтения забыть, в которых соответственно оформление не идет дальше обложки. Реклама в журнале - маленький плакат. В каждом из жанров дизайнер может проявить свой темперамент, свое отношение к материалу, надо только ясно представлять жанр и адрес данного издания. А вот издания классики - Шекспира или Пушкина - требуют осознанного подхода к выбору гарнитур шрифта. Таймc в большинстве случаев не годится (а сейчас подавляющее большинство печатной продукции набирается именно этим шрифтом). Одним словом, очень хорошо, если шрифт соответствует стилю эпохи или стилистике автора. Что такое хорошо, а что такое плохо Набор прописными читается на 12% медленнее прямого строчного начертания. Это связано с тем, что они примерно на 35% шире строчного начертания. Если придерживаться взгляда на процесс чтения как на скачкообразный, то понятно, что за одинаковые по длине "скачки" читатель "проглатывает" меньшее количество букв при наборе прописными. Отчасти это можно объяснить и привычкой - мы привыкли читать книги, набранные строчными знаками. Курсивный набор читается почти так же хорошо, как и прямой, только в средних по длине текстах. То же самое можно сказать про полужирные начертания. Основным наборным шрифтом являются не слишком светлые и средние по жирности начертания. Буквы должны быть черными и печататься по белой или кремовой бумаге. Все остальные варианты с точки зрения удобочитаемости проигрывают. Предупреждение 1! Если вы не хотите, чтобы читатель посылал проклятия на вашу голову, ни в коем случае не применяйте в наборе длинных материалов (две страницы журнального текста и больше) светлых начертаний кеглем 8 пунктов, по черному фону белым или яркими оттенками. На экране все хорошо, но глаза заболят на пятом абзаце. Если все-таки хочется применить мелкий кегль по черному фону, то лучше взять полужирное начертание гротеска. И не больше нескольких абзацев. Предупреждение 2! Прочитать текст без лупы невозможно, если рисунок под текстом растрирован или состоит из иллюзорно-объемной фактуры, а растр или элементы фактуры соразмерны с размером строчных знаков. Объемная фактура во многих случаях является значительно активней фактуры текста, и если это происходит, то есть основания подозревать вас в скрытой неприязни к автору текста. Наиболее удобочитаем для нормально развитого взрослого человека текст, набранный 9-м или 10-м кеглем. Большие кегли заставляют дальше "скакать" при чтении, но рекомендуются при ослабленном зрении. Меньшие кегли читаются с большим напряжением при разглядывании знаков. Специалисты советуют начинать учиться чтению с 36-го кегля. Строки шире 120 мм неприятны более широким разворотом головы в процессе чтения, узкие - неравномерностью межсловных пробелов при выключке ("скачки" с конца предыдущей строки в начало следующей становятся слишком частыми). В строке идеальной ширины умещается 50-55 знаков. Ширина строки может меняться в зависимости от восприятия стилистики произведения оформителем текста, а также других эстетических и экономических факторов. Например, в тексте с частыми абзацами длинная строка менее экономична. Но главное - вкус к шрифтам - результат воспитания, а не врожденное качество. Потому учиться никогда не... Шрифты сейчас, или Наступил ли компьютерный рай? Действительно, с появлением персональных компьютеров началось бурное развитие настольных издательских систем, упростив создание печатных изданий. Это, в свою очередь, значительно увеличило количество малотиражных изданий и людей, которые их делают. Но все равно, сейчас шрифт прежде всего ассоциируется с компьютером, и на второй план уходят художники-оформители и каллиграфы с вечно текущей тушью и рассыпающимися перьями. Да и что говорить, уходит от нас искусство писать. Даже письма все чаще набираются на компьютере и, теряя всякую личностную особенность, безжалостно выводятся принтерами. Сейчас количество шрифтов, которые установлены на компьютере художника-дизайнера, спокойно переваливает за сотню. При этом компьютер совершенно спокойно может менять цвет, размеры и прочие атрибуты шрифта и текста. И теперь то, что было достоянием узкого круга профессионалов, стало доступно всем. Векторные компьютерные шрифты Сам термин "векторные" означает, что все символы шрифта описаны математическими формулами и оттого занимают значительно меньше места, чем, скажем, растровые. В векторном формате символы описываются в системе координат, что в переводе на человеческий язык звучит приблизительно так: - провести прямую из точки х=10, у=20в точку х = 50, у = 80; - построить окружность с центром в точке х = 70, у= 80 радиусом 50; Формат TrueType (TTF) Сейчас это самый популярный для Windows-систем формат шрифта (его полное имя True Type - т.е. в переводе "правдивый, или правильный шрифт"). Формат представления шрифтов TrueType был совместно разработан фирмами Apple и Microsoft для применения в их операционных системах (Mac OS и Windows). По всей видимости, основной причиной разработки нового формата было желание оказаться независимыми от фирмы Adobe - владельца прав на формат Type 1. С другой стороны, по некоторым параметрам Type 1-шрифты не удовлетворяли требованиям, предъявляемым к шрифтам, которые планировалось использовать на устройствах с очень низкой разрешающей способностью, прежде всего для вывода сообщений на мониторы. Основным потребительским свойством TrueType-шрифтов можно считать простоту. Вся необходимая информация о символах находится в одном файле, а процесс установки новых шрифтов прост и нагляден: вы копируете файл шрифта в нужную папку (для Windows обычно это папка С: \Windows\fonts). Причем надо обязательно отметить, что в этом формате один файл - это один шрифт (в отличие от формата Type 1, где на один шрифт в обязательном порядке приходится от двух до четырех файлов). Тот факт, что поддержка TrueType-шрифтов напрямую была включена в Windows и Mac OS - наиболее популярные графические операционные системы, привел к их быстрому распространению. И, несмотря на то, что серьезные полиграфисты по-прежнему предпочитают использовать шрифты Type 1, по числу пользователей TrueType-шрифты их сильно опережают. Формат Type 1 Этот формат был разработан фирмой Adobe специально для фотовыводного оборудования. В том числе обеспечивается поддержка Type 1 в ее программах - Photoshop, Illustrator, Pagemaker, Acrobat. Фирма Adobe - лидер в программном обеспечении для настольно-издательских систем во многом благодаря языку описания страниц PostScript. Сейчас этот язык стал фактически стандартом для передачи графической информации между системами разработки страниц (таких, как программы для обработки изображений, верстки, текстовых редакторов) и системами отображения документов - принтерами высокого разрешения, фотовыводными устройствами и некоторыми другими видами оборудования. Язык PostScript настолько популярен, что теперь целый класс устройств именно так и называется - PostScript-устройства. Шрифты формата Type 1 описаны одноименным специальным языком, который мы назовем совместимым с языком PostScript. По сравнению с True Type разметка шрифта Type 1 существенно проще - в ней вместо указания опорных точек строятся кривые Безье 2-3-го порядка. Это уменьшает количество ошибок и значительно ускоряет вывод шрифта на носители. А с появлением новой технологии PDF (Portable Document Format) у шрифтов Type 1 началась новая жизнь, при том что старой их полиграфической жизни замены еще не существует. Неудобства шрифтов Type 1 Для установки шрифта в систему надо иметь специальную программу управления шрифтами. Самая распространенная - Adobe Type Manager DELUXE 4. 0, которая помимо поддержки формата Type 1 может управлять также и шрифтами True Type. Программа позволяет объединять шрифты в смысловые группы и активировать их в нужный момент (к примеру, если на компьютере работают несколько человек, то каждый из них может активировать нужные именно ему шрифты, экономя ресурсы системы и время загрузки программ). Формат Type 1 имеет два файла (с расширениями PFB и PFM) на один шрифт. Этот формат не поддерживается (и в ближайшем времени не будет) существующими языками разметки Internet-страниц: HTML, XML, в отличие от True Type. Так наступил ли компьютерный рай? Конечно! Если мы будем говорить о технологиях, то полиграфия уже немыслима без компьютера, так же как немыслима без компьютера верстка, набор, редактирование текста, да и в большинстве своем вообще реклама. Технологией будущего справедливо считается Internet, которая целиком завязана на компьютерах и шрифтах и без них существовать не может. Единственный вопрос, на который никогда не будет ответа: а не заменит ли все это компьютерное развитие нам простого человеческого общения? Того самого, для которого и была создана первая буква. Литература: Дмитрий Кирсанов, "Веб-дизайн", Символ-Плюс, 1999; Барышников Г. М., "Шрифты. Разработка и использование". Эком, 1997. Артем Герасимович | ||
ФОРМАТИРОВАНИЕ
M-q Отформатировать абзац Задать левую границу форматирования Задать правую границу форматирования M-x auto-fill-mode Установить/Отменить режим автоформатирования M-x set-variable indent-tabs-mode nil выравнивание делать пробелами M-x tabify Свернуть все пробелы в табуляторы M-x untabify Развернуть все табуляторы в пробелы
Формато-специфичные абзацы
Мы только что увидели, что командой L не так-то легко управлять. А почему мы не можем просто использовать HTML-ссылку? Краткий ответ "потому что POD -- это не HTML" подсказывает решение. Если бы мы могли указать, что этот абзац предназначен для HTML, этот -- для LaTeX, а этот -- для SnaFoo", то мы могли бы использовать разметку, специфичную для этих форматов.
Специальная команда
=for format абзац_текста
указывает транслятору обратить внимание на format перед тем, как он станет обрабатывать абзац_текста. Если транслятор чувствует, что он "отвечает" за обработку формата format, то он его обрабатывает по своим правилам, в противном случае он его полностью игнорирует. Вторая часть названия обработчика обычно указывает, в какой формат он транслирует. Например pod2man работает с =for man, pod2html преобразует абзацы =for html, и т.д.
Всякий раз при использовании формато-специфичного абзаца в документе появляется "ветвление" (поскольку разделы =forformat должны быть созданы для каждого из предполагаемых выходных форматов), тем самым пробивается брешь в стройной структуре документа.
Это обычный абзац, который обрабатывается всеми трансляторами.
=for html <p>Этот абзац появится только в файле обработанном <b>pod2html</b>.</p>
=for latex Тот же самый абзац, но оттранслированный {\bf pod2latex}.
=for text А я предназначен для *pod2text*.
Продолжаем писать для всех и всяких форматов.
Трансляторы игнорируют неизвестные форматы, так что мы можем изобрести абзацы для своих специальных нужд! Например, чтобы закомментировать сразу целый абзац, можно написать:
=for comment Кто-нибудь может разобраться со следующим разделом?
Часто используется формат emacs :-) Для того чтобы при подготовке POD-файла переключить emacs в текстовой режим, начните файл с:
=for emacs -*- text -*-
или закончите его так:
=for emacs Local Variables: mode: text End:
Те пользователи emacs, которые применяют дополнение hyperbole, могут превратить имеющиеся у них "тупые" POD-файлы в связанную гипрессылками коллекцию (на самом деле возможности hyperbole этим не исчерпываются, но гиперссылки -- хорошее начало) файлов следующей командой:
=for hyperbole <(std-reference)>
где <(std-reference)> -- это кнопка hyperbole, которая, стоит по ней кликнуть мышью, переносит вас в другой файл, содержащий документацию по std.
Функции SED
(В скобках указывается максимальное число адресов)
(1) a \text - Добавить "text" после указанной строки (вывести), потом считать следующую.
(2) b label - Перейти на метку, устанавливаемую, с помощью функции ":" , если label пуст, то перейти в конец скрипта.
(2) c \text - Удалить pattern space и вывести "text" на output .
(2) d - Удалить pattern space .
(2) D - Удалить pattern space до вставленной newline .
(2) g - Заместить содержимое pattern space содержимым буфера hold space .
(2) G - Добавить к содержимому pattern space содержимое буфера hold space .
(2) h - Заместить содержимое буфера hold space на содержимое pattern space .
(2) H - Добавить к содержимому буфера hold space содержимое pattern space .
(1) i \text - Вывести текст на output перед указанной строкой.
(2) n - Вывести pattern space на output и считать следующую строку.
(2) N - Добавить следующую строку к pattern space , разделяя строки вставленным newline .
(2) p - Скопировать pattern space на output .
(2) P - Скопировать pattern space до первой вставленной newline на output .
(1) q - Переход на конец input . Вывести указанную строку, (если нет флага -n ) и завершить работу SED .
(2) r rfile - Читать содержимое rfile и вывести его на output прежде чтения следующей строки.
(2) s - Функция контекстной замены. (См. 5.)
(2) t label - Перейти на метку, устанавливаемую с помощью функции ":" , если для этой строки была осуществлена замена с помощью функции "s" . Флаг осуществления замены восстанавливается при чтении следующей строки или при выполнении функции "s" .
(2) w wfile - Добавить pattern space к концу файла wfile . (Максимально можно использовать до 10 открытых файлов.)
(2) x - Поменять местами содержимое pattern space и буфера hold space .
(2) y /str1/str2/ - Заменить все вхождения символов из str1 на соответствующие из str2 . Длины строк должны быть равными.
(2) ! func - Применять функцию func (или группу функций в {} ) к стокам НЕ попадающим в указанные адреса.
(0) : label - Устанавливает метку для перехода по "b" и "t" командам.
(1) = - Выводит номер строки на output как строку.
(2) { - Выполняет функции до "}" , только когда выбрано pattern space . Группировка функций.
(0) - Пустая команда игнорируется.
# - Комментарий.
( "#n" в скрипте равносильно установке флага -n )
Функция контекстной замены
Формат:
(2)s/< Регулярное выражение > /< Замена > /< флаги >
Функция s заменяет вхождение < Регулярного выражения > в pattern space на < Замену > .
< Регулярное выражение > : Аналогично выше данному, но может быть заключено не в "/ /" а в любые другие символы (не " " (пробел) и не newline ).
< Замена > : Любой набор символов. Используются специальные символы:
"& " - Заменяется на строку, указанную в регулярном выражении.
"\d" - , где d - цифра, указывает на d -тое выражение, заключенное в "\(","\)" в регулярном выражении.
< Флаги > :
g - Глобальная замена: заменить все вхождения в строке.
p - Печатать (выводить на output ) строки, в которых была осуществлена замена.
w wfile - Выводить в файл wfile строки, в которых была осуществлена замена.
Примеры:
s/to/by/w changes - Заменить в тексте первое вхождение "to" в каждой строке, если таковое есть, на "by" и измененные строки сохранить в файле "changes" .
/iiii/s/[Oo]lga/ Olga V.Galina/p - Заменить в тексте, в строках, где встречается вхождение "iiii" , первое вхождение подстроки "olga" или "Olga" на " Olga V.Galina" , при этом измененные строки выводить на печать.
s/[.,;:?]/*sign& *sign& **/g - Заменить в тексте каждое вхождение одного из знаков ".,;:?" в строку на "*sign& *" , где & будет тем знаком, который стоял прежде, например, "." на "*sign.*" , "?" на "*sign?*" и т. д.
Функция setlocale() .
Основной функцией POSIX locale
API является функция . Данная функция определена в #include файле как :
char *setlocale(int category, const char * locale);
Существует три основных формы вызова этой функции :
setlocale(LC_XXX,"language_TERRITORY.Codeset");
setlocale(LC_XXX,"");
str=setlocale(LC_XXX,NULL);
Первая форма применяется для установки конкретной категории локализации в конкретное значение.
Вторая форма применяется для установки категории локализации "по умолчанию". В этом случае значение категории локализации берется из переменных окружения.
Третья форма - это скорее форма GET - позволяет получить текущее значение категории локализации.
Функциональность
Чтобы получить представление о возможностях редактора надо просто просмотреть выпадающие меню. Наиболее интересный пункт - Insert. Рассмотрим его :
- picture - вставить графическое изображение ( Ted поддерживает 13 форматов ), среди которых присутствуют используемые в Windows - ico, .bmp, .wmf. Размер изображения можно изменить с помощью 8-ми точек расположенных по границам и появляющихся при двойном клике на изображении.
Изображение 6, графические объекты в TED. Кликните на изображении для детального просмотра.

Можно конечно изменить размеры изображения, но рекомендуется не делать этого из соображений потери качества.
- symbol - выбрать и вставить специальный символ из таблицы символов. Просто выбираем символ, нажимаем insert и он оказывается в документе в позиции курсора.
Изображение 7, symbols. Кликните на изображении для детального просмотра.

- hyperlink - вставить гиперссылку.
- bookmark - добавить закладку.
- file: вставить RTF файл
- table: создать таблицу.
В пункте меню Format содержатся команды для форматирования текста : расположение ( слева, справа, по центру ), добавление пустой строки до и после параграфа, создание набора правил о формате данного параграфа ( Copy rules ) и применение их для других (Paste rule).
Следующий пункт меню - Tools :
-Font Tool: выбрать шрифт, размер шрифта, просмотреть изменения перед их применением.
-Find поиск и замена текста.
-Spelling: орфографический словарь, использующий файл /usr/local/ind/Lang.ind. Существуют словари почти для всех Европейских языков. Словарь для использования по умолчанию указан в файле ресурсов, но данный пункт меню позволяет выбрать любой из установленных.
- Page Setup выбор размера листа бумаги и полей.
- Insert Symbol вставить специальный символ.
- Table Tool создать таблицу и вставить ее в документ.
Изображение 8, таблица в Ted. Кликните на изображении для детального просмотра.
Также Ted обладает следующими функциями : Mail, Hyperlinks и Bookmark. Последние две интересны для сохранения файла в формате HTML, для чего необходимо выбрать пункт меню Save to из File. Можно сохранить файл в форматах .txt и .html несмотря на то, что Ted открывает файлы только в формате RTF.
Когда файл сохраняется в формате html сохраняются также и изображения в каталоге с расширением .img. Например изображения, относящиеся к файлу toto.html находятся в каталоге toto.img.
Есть ли еще какие - нибудь дополнительные возможности у редактора Ted? Конечно есть, но я советую вам самостоятельно попробовать их : отправить почту непосредственно из редактора, перенести информацию между данным приложением и другими X11 приложениями...
Гиперссылки
Когда на сцене появляюстя гиперссылки, мы сталкиваемся еще с одной проблемой, похожей на ту, с которой мы столкнулись при обработке перекрестных ссылок. Для HTML версии документа гиперссылки жизнено необходимы, в печатной -- не слишком полезны: сравните "Щелкните мышью вот здесь" и "Нажмите карандашом на эту букву". Но иногда, автору действиотельно требуется включить URL в печатный текст. latex2html предоставляет две команды, которые позволяют это сделать.
\htmladdnormallink{текст ссылки}{универсальный локатор ресурса}
\htmladdnormallinkfoot{текст ссылки}{универсальный локатор ресурса}
В HTML версии обе команды генерируют гиперссылку вида <a href = "URL">текст ссылки</a>. В LaTeX версии первая только вставляет текст ссылки, полностью подавляя вывод части URL. Вторая команда добавляет к этому сноску, содержащую универсальный локатор ресурса. Типичным примером применения этих команд может служить следующий
Текст этой статьи можно скачать с нашего \htmladdnormallink{веб-сайта}{http://www.linux-gazette.org}.
и
Текст этой статьи можно скачать с нашего \htmladdnormallinkfoot{веб-сайта}{http://www.linux-gazette.org}.
в LaTeX результат первой команды будет
Текст этой статьи можно скачать с нашего веб-сайта.
во втором варианте веб-сайт дополняется маркером сноски, а сама сноска с URL помещается внизу страницы. HTML в обеих случаях выглядит так
Текст этой статьи можно скачать с нашего веб-сайта.
Главные характеристики
Я не собираюсь даже попробовать дать детальное и скучное описание всех возможностей, что, с моей точки зрения, наиболее привлекательно.
Есть множество on-line примеров и help'ов. Руководства написаны в LyX и могут читаться прямо в LyX. К счастью, руководства написаны для знающих пользователей, они не предполагают что пользователь совершенно несведущ и не поясняют, что есть "bold" и как использовать мышку. С таким руководством можно стать профессионалом в LyX в короткое время за несколько страниц. Скорость инструментов поиска и перемещения особенно впечатляет.
Таблицы полностью автоматические и WYSIWYG. Размер сетки регулирутся автоматически. Можно вставлять, удалять и вклеивать столбцы и строки; выравнивать текст; обединять и разъединять сетки... Это то, что вы можете найти и в других редакторах.
Также можно вставлять изображения и таблицы как "плавающие" объекты. Плавающий объект - это объект, который можно перемещать(если это необходимо) из его настоящего положения, включая целые страницы. К примеру, желательно чтобы изображения появлялись в начале страницы, где на них ссылка. Плавающие обекты могут иметь как заголовок так и ярлык, так что на них можно ссылаться из других мест. Во время компиляции документа, LaTeX присвоит номер каждой фигуре и таблице, обновит все ссылки, и создаст список изображений и таблиц.
Можно вставлять сноски также как и заметки на полях. Заметки на полях - удобное средство которого нет в других редакторах. Заметки также плавающие объекты, поэтому нам не следует беспокоиться о их положении. Другое интересное свойство - это возможность вставить что вам угодно в заметки(таблицы, изображения, уравнения, и тд), исключая еще одну заметку.
Для проверки правописания LyX снабжен инструментом ispell (утилита которая доступна во всех дистибутивах). Операция проверки правописания схожа c теми которые есть в других редакторах: каждое неправильное слово подсвечивается и список альтернативных слов вам предлагается для замены.
LyX использует новаторский механизм ссылок на объекты(секции, изображения, таблицы,...). Вы можете вставлять ярлыки в лубое место, и затем вставлять ссылки на них. Во время редактирования ссылки действуют как URL адресс, так что когда вы кликаете их, курсор переноситься в место где ярлык определен. В конечном документе, метки удаляются и ссылки заменяются на номер секции, изображения из табллицы (или номер страницы, в зависимости о типа ссылки).
А теперь самое лучшее: математика. То, что я собираюсь сказать не преувеличение, нет другого такого простого и интуитивного способа писать уравнения и с такими впечатляющими результатами при печати. Эта возможность LyX очень ценна. Обычно, другие издатели могут справиться с некоторыми комплексными математическими выражениями... Теперь попробуйте LyX, и призудамайтесь над математическими выражениями выходящими за грань реальности: множество подиндексов, интегралы, иррациональные числа, стрелки, системы уравнений, массивы, и тд. А теперь напечатайте это... и наслаждайтесь! Если вы знаете LaTeX тогда вы можете писать выражения таким же образом, и LyX изобразит их находу!
Я еще не подметил, но это очевидно, LyX разбивает на главы, секции, подсекции, и тд, и с помощью этой информации LaTeX может построить индексный указатель в конечном документе.
Я уже говорил что благодаря хорошей on-line помощи время обучения довольно короткое. Другое усоверщенствование, помогающее изучению LyX - умное использование клавиатуры, мышки и меню. Нет необходимости изучать два различных способа произведения одних и тех же действий(клавиатурой и мышкой). Можно кликнуть в меню "File", а потом "Save", но также можно нажать "Alt-F" и "S" (меню не откроется), чтобы выполнить те же действия. С другой стороны, большинство простых операций доступны через обычные команды "Control": <Ctrl>-C - копировать; <Ctrl>-V - вклейвать; <Ctrl>-F - поиск & замена.
Emacs для начинающих
Говоря о текстовых редакторах, разработанных специально под UNIX, в первую очередь упомянем Emacs, который распространяется бесплатно в рамках проекта GNU. Некоторые компании распространяют его на коммерческой основе, исправив имеющиеся ошибки и адаптировав под конкретные платформы с некоторыми улучшениями возможностей "родного" Emacs. Таковым, например, является GNU Emacs 19.19 фирмы Ready-to-Run Software, который распространяется в составе пакета утилит обработки текста. Безусловно, данный редактор предназначен для квалифицированных программистов, обладая мощными средствами разработки программ. Однако GNU Emacs требует основательного изучения; для расширения его возможностей приходится программировать на языке LISP, что не очень нравится даже квалифицированным программистам, а уж обыкновенным пользователям - тем более. Для поклонников Emacs могу сообщить, что исходные тексты версии 19.28 появились на prep.ai.mit.edu: в каталоге pub/gnu.
Emacs для начинающих
Gnus -- МБч ъпзуБ Emacs, ЮпвЮпячБпщщКы р ъуЮрЦН чГуЮутЛ тшО ГБущьО ь чБъЮпрзь щчрчАБуы Usenet. ¦сч Бпзжу эчжщч ьАъчшЛвчрпБЛ тшО ГБущьО ь щпъьАпщьО чБруБчр щп АччяИущьО ьв эщчсьЕ тЮЦсьЕ ьАБчГщьзчр -- ъчГБК, ЦтпшущщКЕ зпБпшчсчр, тпытжуАБчр ь тЮЦсьЕ.
TтуАЛ эК тпуэ ррутущьу р Gnus ь чъьАКрпуэ щузчБчЮКу чАщчрщКу рчвэчжщчАБь. ¦шО ъчшЦГущьО ъчтЮчящчы ьщДчЮэпФьь ч Gnus щпяуЮьБу M-x info ь рКяуЮьБу впБуэ ЮЦзчрчтАБрч ъч Gnus.
гБчяК впъЦАБьБЛ Gnus, щпъуГпБпыБу M-x gnus RET.
Гримасы русификации
Выше уже было отмечено, что специально заниматься русификацией TeXmacs как будто бы нет необходимости: всё уже сделано за нас. Более того: хотя в TeXmacs изначально предусмотрена поддержка ряда языков, русский удостоился особого внимания. В меню обнаруживается несколько специальных команд, имеющих отношение к работе с кириллицей, а методике такой работы посвящено отдельное электронное руководство. Тронутый такой заботой, пользователь принимается вводить текст и: наблюдает на экране хорошо знакомую бХОПНю. По крайней мере, в том случае, если в его системе принята кодировка koi8. Попутно обнаруживается, что нельзя пользоваться и английской клавиатурой: пока мы не пометим текст явным образом как английский (это делается через меню -> ), вместо латинских букв будут печататься соответствующие им русские.
Первую проблему можно легко исправить, если выбрать в меню -> -> пункт . Но не делать же это в каждом сеансе? Поэтому остается залезть в файл $TEXMACS_PATH/progs/init.scm, управляющий начальной загрузкой инициализационных сценариев. Там в числе прочего обнаруживаются следующие две строчки:
(exec-file "$TEXMACS_PATH/progs/keyboard/russian" "translit.scm") (exec-file "$TEXMACS_PATH/progs/keyboard/russian" "cp1251.scm")
Первая строка как раз и заставляет английскую клавиатуру работать в качестве русской раскладки, что может быть полезно для тех, кому приходится иметь дело с русским языком в системах с иной локализацией. Мы же можем ее безбоязненно закомментировать. Что же касается файла cp1251.scm, то он является практически пустым, и, в сущности, не нужен даже в том случае, если наша система локализована на базе этой кодировки. (Вернее, в нем содержится один маленький фокус с буквой , смысл которого станет ясен из дальнейшего). Если же вы используете koi8, то замените название этого файла на koi8.scm. После чего поведение как русской, так и английской клавиатуры в TeXmacs придет в норму.
Но не обольщайтесь. Ибо установили вы не раскладку для koi8, а как раз наоборот: переходник с koi8-клавиатуры на кодировку cp1251. Именно она будет использоваться для отображения текста на экране и записи его в файл. В той же кодировке составлен файл переносов и файл $TEXMACS_PATH/langs/natural/dic/english-russian.scm, отвечающий за русификацию интерфейса. Что, в общем-то, лично меня ни в коей мере не угнетает, поскольку сам я работаю исключительно с cp1251. Да и как же иначе? Не говоря уж о том, что данная кодировка является наиболее логичной, только в ней имеются все необходимые типографские символы, (типа парных кавычек) без которых нет смысла говорить о полиграфическом качестве оформления текста. Однако же давайте задумаемся, почему автор программы (или автор ее русификации) предпочел выбрать именно эту кодировку? Оказывается, по одной единственной причине: cp1251 совместима с кодировкой кириллических шрифтов для TeX, которые по умолчанию используются в TeXmacs. И сделать так пришлось потому, что TeXmacs, будучи WYSIWYG-приложением, не предусматривает механизма перекодировки входного файла, подобного тому, который обеспечивается загрузкой пакетов fontenc и inputenc в LaTeX. То есть навязывают нам, в сущности, вовсе не cp1251, а TeX'овскую кодировку T2A.
Но ведь такой подход не только идеологически неверен, но и весьма наивен. Ну хорошо, cp1251 совпадает с T2A в русской части (и то кроме буквы - не зря же для ее печати понадобилось переопределять поведение клавиатуры), но ведь это уже не будет соответствовать истине для символов других славянских алфавитов. А что, если мы пожелаем сделать украинскую или сербскую локализацию? Неужели напрямую писать текст в T2A? Текст, который нельзя будет прочесть никаким , ибо внутренние кодировки TeX вообще-то предназначаются только для откомпилированных файлов .dvi. Никто и никогда не допускал мысли о возможности использовать их напрямую для набора текстов. Главная причина этого достаточно очевидна: в таких кодировках активно используются те ячейки кодовой таблицы, которые вне системы TeX зарезервированы за управляющими кодами и, соответственно, не должны применяться в текстовых файлах.
Увы, похоже, что данное соображение нисколько не смущает автора TeXmacs. Так, в файле $TEXMACS_PATH/progs/keyboard/accents.scm (он отвечает за некоторые общие параметры клавиатуры) встречаем несколько строчек приблизительно следующего вида:
("- - -" " ")
Приведенная строка задает клавиатурную комбинацию для печати символа . А вот то, что мы обозначили как пробел в кавычках - это на самом деле символ с десятичным кодом 22, который соответствует этому самому длинному тире в латинской кодировке для TeX T1 (равно как и в кириллической T2A). И дело даже не в том, что вносить изменения в подобный файл будет сложно без шестнадцатеричного редактора. Но интересно знать, как бы автор выкручивался из положения, если бы ему понадобился символ с кодом 12 (прогон страницы)? Или с кодом 13 (перенос строки)? А ведь на привязку символов к данным кодам в TeX нет никакого запрета.
Еще одна любопытная вещь обнаружится, если мы попробуем преобразовать подготовленный в TeXmacs документ в формат LaTeX. TeXmacs предусматривает такую возможность, хотя автор честно признается, что качество конвертера пока оставляет желать лучшего. Открываем полученный файл в текстовом редакторе, и: первым делом обнаруживаем, что строчная буква всюду превратилась в заглавную. Заглавное же вообще стало двойным латинским S. Речь, естественно, идет о тексте в cp1251, в противном случае проблема возникла бы с твердым знаком. В чем тут дело? Оказывается, мы опять расплачиваемся за неуклюжую попытку учесть различия между кодировками, на сей раз латинскими: TeX'овской T1 и общепринятой iso-8859-1. Лечится такое поведение путем истребления из файла $TEXMACS_PATH/progs/convert/tmtex.scm следующих двух строчек:
((equal? c #\337) (tmtex-text-sub "SS" l)) ((equal? c #\377) (tmtex-text-sub "Я" l))
Но не забавно ли, что, ради того, чтобы сделать документ понятным для LaTeX, приходится перегонять его из внутренней TeX'овской же кодировки в общепринятую? И, как видим, проблема вовсе не ограничивается русификацией, ибо различия между двумя западноевропейскими кодировками - приблизительно такого же порядка, как между cp1251 и T2A.
Help
Встроенная помощь редактора NEdit весьма богата, что можно видеть из простого перечисления содержания этого пункта меню. Он содержит:
Getting Started - краткое описание основных особенностей программы; Basic operations, где описаны приемы выделения текста (Selecting Text), поиска и замены фрагментов (Finding and Replacing Text), их вырезания и вставки (Cut и Paste), использование мыши (Using the Mouse), комбинации горячих клавиш (Keyboard Shortcuts), а также формат файлов NEdit (File Format); Features for Programming, то есть фичи для программеров; не будучи таковым, задерживаться здесь не буду; Regular Expressions, на что также распространяется вышесказанное; здесь весьма подробно описаны синтаксис регулярных выражений и прочие их особенности, а также приведены примеры; с этим надеюсь разобраться в будущем; Macro/Shell Extensions, напротив, заслуживает всяческого внимания; именно здесь подробно описаны: использование скриптов оболочки командной строки, процесс протоколирования макрокоманд, синтаксис встроенного макроязыка NEdit и прочее; Customizing - не менее интересная позиция; под этой рубрикой приведены сведения о всех видах настройки NEdit; что составит предмет следующего раздела; NEdit Command Line - описание параметров для запуска NEdit; большая их часть достигаемых таким путем опций может быть реализована также и черех настройки; Server mode and nc - описание использования NEdit в режиме клиент/сервер; Crash recovery - описание действий в экстремальных ситуациях.
Кроме перечисленного, в пункте Help содержатся подробные сведения о текущей версии редактора, политике его распространения, приведены списки рассылки и небольшой перечень проблем и ошибок.
Пора, однако, заканчивать с рассмотрением главного меню. Поскольку в NEdit существует еще и меню контекстное (в терминологии NEdit - Window Background Menu), вызываемое, как положено, щелчком правой клавишей мыши на выделенном фрагменте текста. Правда, оно достаточно простое, содержат лишь пункты Undo и Redo, Cut, Copy и Paste, что в комментариях не нуждается. Однако, как будет показано ниже, и оно может быть настроено.
Таким образом, из рассмотрения меню функциональность Nedit в первом приближении становится ясна. Он обладает очень развитыми средствами ввода и редактирования текстов как общего содержания, так и исходных текстов на языках программирования и разметки. Меню его организовано логичным и привычным для пользователя Windows способом, комбинации горячих клавиш многочисленны и обычно имеют простой мнемонический смысл. Все это, вместе с мощной системой помощи, делает NEdit простым в освоении.
К недостаткам Nedit (или, вернее, особенностям, которые могут не нравится), можно отнести отсутствие инструментальной панели с кнопками и открытие каждого файла в собственном окне (а не в том же самом, с перемещением через систему закладок, например). Впрочем, и тот, и другой момент - спорны: отстутствие кнопочной панели, как я уже говорил, компенсируется системой горячих клавиш, а перемещение между отдельными окнами, хотя и приводит к загромождению дисплея, не менее удобно, чем между закладками. Едиственно, не помешала бы возможность аранжировки открытых окон, но этого можно обычно добиться средствами большинства оконных менеджеров.
Еще в Nedit нет штатных средств управления проектом. Хотя бы в элементарном исполнении, то есть в виде открытия и сохранения группы связанных файлов (глав книги, например, или серии web-страниц). Тем не менее, все это не перечеркивает высоких достоинств редактора.
Однако мало было бы проку от богатства возможностей редактирования, если бы они не сопровождались адекватным богатством настроек. Что же, посомтрим, каковы они, возможности настройки.
ХОЖДЕНИЕ ПО ФАЙЛАМ
^X ^F Войти в файл по запросу ^X ^V Войти в файл по запросу в том же окне ^X 4 ^F Войти в файл по запросу в другом окне ^X ^S / S Сохранить файл / все файлы ^X ^C Выйти из всех файлов с сохранением M-~ Забыть что файл был изменен ^X ^W Записать файл под другим именем write-file M-x<имя файла> Поменять имя файла после записи ^X ^D<каталог> Список файлов в каталоге ^X d Dired режим ^U ^X ^D<каталог> Список файлов в каталоге M-x view-file Просмотр файла M-x insert-file Вставка файла ^X ^S / S Сохранить файл(ы)
Including LaTeX definitions in txt2html
Often, when using LaTeX, it is desirable to have a seperate file with shorthand definitions that are used in formulae. Such definitions can be defined in html by supplying them in a file and entering the name of the file on the command line. For example
txt2html file.txt extras.tex
will include extras.tex in all mathematical symbols produced by LaTeX.
Versions for DOS, WINDOWS and
Russian codepage convertor version 3.11
(c)w_re rusconv v.3.11
IT IS LIKELY:
Distributed free with commented sources. Versions for DOS, WINDOWS and UNIX. Works with encodings: alternative (DOS, cp866), KOI-8 (UNIX), windows (cp1251), macintosh and latinica (russian text spelled latin letters). Converts files between DOS/windows and UNIX text file formats. Files can be converted to several encodings simultaneously. Any number of files can be converted simultaneously. Long file names and local network files support. For most often tasks - converting general russian text from DOS to UNIX, from Windows to UNIX and back - it is enough only one flag. Distributed with utility, which recognizes file encoding. Easy to use in command scripts.
DOCUMENTATION:
IN NEXT VERSIONS:
Graphic user interface. Smart HTML-files converting.
FEEDBACK:
you can put suggestions, wishes, comments on rusconv.
Program distributed free, but register to inspire us on new version get updates and new versions. get information about new utilities.
Author can be contacted by E-MAIL .
LICENSE:
You can free redistribute rusconv and whatrus under condition that you don't change archives (rscnv311.zip, rusconv.3.11.zip or rusconv.3.11.tar.gz). It is good idea to inform us about it. If you make moneys on distributing, it will be very likely if you will send us some of them. Rusconv and whatrus sources can be used in your projects, but you should not create you own versions of rusconv and whatrus. It is no guarantee that rusconv and whatrus always work properly, can't damage information, free from viruses.
HAVE A NICE WORK!
index-e.html
Document created by Oleg A. Paraschenko
Last changes - 15 November 1998
Info? Это что?
Info -- это файлы в ASCII-формате с возможностью перехода между связанными гиперссылками различными документами и удобные для просмотра на экране. При проектировании предполагалось, что формат будет переносимым между всеми платформами, на которых возможно выполнение программ проекта GNU. Info ориентирован на текст, так что файл Info можно просмотреть и в консоли текстового режима. Высококачественная графика доступна только при выводе на печать. Таким образом, формат Info дублирует возможности HTML, за вычетом некоторых графических добавок. Тем не менее, texi2html(1) может преобразовывать исходники Texinfo (.texi) непосредственно в HTML, о чем можно прочесть в разделе .
ИНФОРМАЦИЯ
M-x what-page M-x what-line M-= / ^= размер файла / позиция курсора ^X l о странице
Информация к размышлению
Я только слегка затронул тему SGML и его применения. Тех, у кого есть доступ к Интернет, могут заинтересовать следующие ресурсы.
Информация о месте текущего элемента в иерархии документа
В главе "Настройка переменных редактора Emacs" говорилось о необходимости присвоения ненулевого значения переменной sgml-live-element-indicator, чтобы сообщить PSGML о необходимости отображения типа документа и имени текущего элемента в строке состояния. Более подробную информацию о месте текущего элемента в общей структуре документа, можно получить с помощью команды sgml-show-context (C-c C-c). Информация о месте текущего элемента в иерархии документа выводится в окне минибуфера.
| <sect1> <title>Biographical</title> <para>Queequeg was a native of <emphasis>Kokovoko</emphasis>, an island far away to the West and South.</para> |
Например, переместите курсор в приведенном выше тексте на слове "Kokovoko" и нажмите C-c C-c. В окне минибуфера появится следующее сообщение:
| #PCDATA in emphasis in para in sect1 in chapter |
Альтернативный вызов - пункт Show Context меню SGML.